About This Site
Software development stuff
Archive
- 2017
- 2016
- 2015
- 2014
- 2013
- 2012
- 2011
- 2010
- 2009
- 2008
- 2007
|
Entries tagged "linux".
Sat, 04 Oct 2008 08:08:14 +0000
CGI is a standard protocol to run dynamic web-apps using HTTP protocol. It's advantage: standard, available everywhere, disadvantages: it's slow (a process is created for every HTTP request). To overcome this limitations FastCGI has been created (one process serves many HTTP requests). But not everywhere FastCGI is supported. I'll show how to use special bridge to use FastCGI on CGI-only environment.
First, we have to download current FastCGI development kit then compile cgi-fcgi binary usging the same architecture as our hosting provider uses. Then copy compiled binary to server and create small script to run our bridge, lets name it app.bridge:
#! ./cgi-fcgi -f
-connect app.sock app.fcgi 1
Here "1" means: create one process, multiple requests will be handled by internal thread manager in application. If your application is not multi threaded you can pass higher number here.
The bridge file must have correct permissions and the following fragment must be added to .htaccess to allow to call this bridge script:
Options +ExecCGI
AddHandler cgi-script .bridge
That's all, folks!
Mon, 29 Dec 2008 21:33:21 +0000
Few days ago I bought new small VPS box ( OpenVZ, 128 MB RAM) in order to place there a new monitoring node of my site monitoring system. Such small amount of RAM is a challenge for operating system optimisation techniques (OpenVZ doesn't have "swap" as Xen does).
First of all I discovered that apache2-mpm-worker (Apache implementation that uses threads) consumes more memory (100MB) than the classic version that use separate processes (20MB). I had to switch to apache2-mpm-prefork version then.
Next unpleasant surprise: small Python app eats 100MB of virtual memory! I checked that virtual (not resident) memory is taken into account by VPS. I applied some tools to locate memory bottleneck, but without success. Next I added logs with current memory usage to track call that causes big memory consumption. I tracked the following line:
server = WSGIServer(app)
is guilty for high memory increase. After few minutes of googling I located problem: default stack size for a thread. Details:
- This line creates few threads to handle concurrent calls
- Stack size is counted towards virtual memory
- Default stack size is very high on Linux (8MB)
- Every thread uses separate stack
=> multi threaded application will use at least number_of_threads * 8MB virtual memory!
First solution: use limits.conf file. I altered /etc/security/limits.conf file and changed default stack size. But I couldn't make this change to alter Python scripts called from Apache (any suggestions why?).
Second (working) solution: lower default stack size using ulimit. For processes launched from Apache I altered /etc/init.d/apache2 script and added:
ulimit -s 128
Now every thread (in apache / Python application) will use only 128 kB of virtual memory (I lowered VSZ from 70 MB to 17 MB this way). Now I have additional space to enlarge MySQL buffers to make DB operations faster.
UPDATE: There's better place to inject ulimit system-wide: you can insert this call in:
/etc/init.d/rc
script. Then ulimit will be applied to all daemons (as Apache) and all login sessions.

Tue, 10 Feb 2009 10:53:34 +0000
Backup Whole Filesystem
The simplest solution is to make whole filesystem dump and store it using one big tar file. This solution has few drawbacks:
- Making backup is slow and consumes huge amount of server resources
- Transferring this backup off-site consumes your bandwitch (you pay for it), so you cannot do it very often
- Restoring backup is slow (you have to transfer back the dump)
How can we do frequent backups without above problems? There's an answer:
Incremental Backup
What is an incremental backup? It's method of creating archive that collects only changed files since last backup. During typical operating system usage only small percent of files changes (database files, logs, cache etc.), so we can backup only those files.
Second optimisation we can use is to backup only files that can't be reproduced from operating system repositories (for example: most binary files in /usr/bin come from operating system packages and we can easily recreate them by using standard operating system installation methods. Third optimisation is to skip files that will be automatically regenerated by our application (cache) or doesn't play critical role for our system (some debug logs laying around). Let's see some code that can do such task:
/home/root/bin/backup-daily.sh:
function backup() {
tgz_base_name=$1
shift
_lst_file=$DIR/$tgz_base_name.lst
_time=`date +%Y%m%d%H%M`
if test -f $_lst_file
then
_tgz_path=$DIR/$tgz_base_name-$_time-incr.tgz
else
_tgz_path=$DIR/$tgz_base_name-$_time-base.tgz
fi
tar zcf $_tgz_path -g $_lst_file $*
}
backup etc etc
backup home home
backup var var
Automated Backup
If you're manually doing backups I'm sure you will forget about them. It's a boring task and IMHO should be delegated to computer, not to a human. UNIX world have very sophisticated and very helpful daemon called cron. It's responsible for periodically executing programs (typical maintenance tasks done in your system: rotating logs for example). Let's see crontab entry for backup task: 31 20 * * * nice ~/bin/backup-daily.sh Backup creation will be executed every day 20:31. The next step is to collect those backup outside the server. It's easy. Setup similar cron task on separate machine that will rsync (use SSH keys for authorisation) your backups off-site.
Test If Your Backup Is Working Properly
So: you've just created automatic backup procedure and you want to stand still. DON'T!!! Your backup must be checked if it's sufficient to restore all services you're responsible for after a disaster. The best way to do that is to try restore your systems on a clean machine. We have, again, few options here:
- setup dedicated hardware and install here clean system
- setup virtual server using virtualisation technology
- use chroot to quickly setup a working system
Options are ordered from "heaviest" to "easiest". Which one to choose? Personally chroot is my preferred option. You can easily (well, at least under Debian) setup "fresh" system and test restore procedure.

Wed, 09 Sep 2009 21:08:50 +0000
The story
After few months with a2b2.com without VPS panel (see: HyperVM exploit story) i decided to say bye-bye and move my monitoring node to another host. I selected small company fivebean.com for this purpose.
 First I thought about VPS but then saw few interesting options mentioned on shared hosting offer: First I thought about VPS but then saw few interesting options mentioned on shared hosting offer:
Ruby on Rails (FastCGI), PHP 5.2.9 (IONCube/Zend Optimizer), mySQL 5.0.67, Perl 5.8.8, Python 2.4.3, GD Graphics Library, ImageMagick 5+, CGI-BIN, SSI (server side includes), Trac, Subversion and more!
Looks like we have long running processes-friendly hosting! I asked them about rules and got the answer:
The CGI processes are executed by suexec and would run as the user (script owner). We currently do not have any process limitations on scripts but we do have
scripts that monitor for high usage and in which case we work with the user to resolve. If you have any other questions please let us know.
Seems very interesting. I appreciate hosts that control resource usage (CPU/disk) because that lowers possibility of abusing all resources on a server by one customer. Good.
Offer
The offer is pretty good: $1.02/mo when paid for one year in advance. Compare it to Dreamhost: $8.95/mo* or Bluehost: $6.95/mo. The servers are in Chicago:
8. ae-72-72.ebr2.Frankfurt1.Level3.net 0.0% 53 43.1 43.3 41.8 54.0 2.2 ae-92-92.ebr2.Frankfurt1.Level3.net
9. ae-43-43.ebr2.Washington1.Level3.net 0.0% 53 141.8 142.6 139.9 153.2 1.8
10. ae-2-2.ebr2.Chicago2.Level3.net 0.0% 53 142.7 143.4 142.3 144.4 0.5
11. ae-5.ebr2.Chicago1.Level3.net 0.0% 53 142.7 146.6 141.0 155.5 4.6
12. ae-24-52.car4.Chicago1.Level3.net 3.8% 53 213.5 150.6 140.8 282.8 30.2
13. WBS-CONNECT.car4.Chicago1.Level3.net 0.0% 53 146.9 147.2 145.3 161.5 2.4
14. 208.79.234.18 0.0% 53 161.6 167.9 160.5 295.5 20.2
15. 209.188.90.57 3.8% 53 162.0 163.9 160.6 193.9 5.7
16. maui.fivebean.com 0.0% 53 163.6 165.5 160.8 176.0 3.4
Ping is about 160 ms from Warsaw. Not bad.
I paid using PayPal and have running account in minutes.
Environment Details
I checked for limits under ssh:
$ ulimit -a
core file size (blocks, -c) 200000
data seg size (kbytes, -d) 200000
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 200704
max locked memory (kbytes, -l) 32
max memory size (kbytes, -m) 200000
open files (-n) 100
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 20
virtual memory (kbytes, -v) 200000
file locks (-x) unlimited
Parameters that shows some restrictions relevant to me:
- Max memory size (RSS): restricted to 200 MB. It's okay for me because my scripts often use less than 20 MB of RSS
- Maximum open files: 100 concurrent opened descriptors - seems reasonable
- Maximum user processes limited to 20: it may influence multi threaded applications. Monitoring processes are started as separated threads, so I have to limit concurrent measurements accordingly
- Virtual memory: it may influence multi threaded applications with big stack size
I asked if max user processes could be raised but got the answer:
To maintain stability cpanel sets this limit as a hard value and unfortunately we cannot modify it at this time. We apologize for any inconvenience.
I discovered that no quota was configured on my account:
$ quota -v(no output)
Seems not all aspects of server are configured properly. Another issue is with SSH login time:
$ time ssh fb ls(...)
real 0m52.980s
user 0m0.032s
sys 0m0.012s
It's weird, another host with "Turbo" package seems to be much faster:
$ time ssh gamma ls(...)
real 0m2.505s
user 0m0.028s
sys 0m0.008s
Slow SSH connection states bolded out:
debug1: Next authentication method: publickey
debug1: Offering public key: /home/(...)/.ssh/id_rsa
debug1: Server accepts key: pkalg ssh-rsa blen 149
debug1: read PEM private key done: type RSA
debug1: Enabling compression at level 6.
debug1: Authentication succeeded (publickey).
debug1: channel 0: new [client-session]
debug1: Entering interactive session.
No idea what is broken (a network timeout somewhere)?
Another issue is random restarts. Apache is restarted from time to time. I suspect there's automated watchdog that kill processes that use too much resources, Here you can see more timing information from FastCGI process (Trac instance) on this machine. Below one week monitoring with 5 minutes interval result:

Support
Few things have to be adjusted by support ticket:
- SSH was disabled by default - they enabled it for me
- Crontab was blocked - it was enabled, too
- Few system Python-related libraries was missing - were added in minutes
I evaluate support quality as very good.
Panel
It's a regular shared hosting so you can use user-friendly tools like CPanel. It's classic tool for such task and is pretty intuitive in usage.

My presonal preference is shell, so I use it if possible (e.g. crontab edits).
Summary
So far, so good. You can check how this deployment is working under this address (It's a node from monitoring system site-uptime.net, BTW). I'll write more details about hosting after few months of usage.
VPS also is considered to be checked, I'll write more details after setup.
To sumarize:
- + cheap economical offer
- + Trac/Subversion out of the box
- - slow SSH login
- - frequent (few times a week) short (<few minutes) downtimes
Sun, 04 Oct 2009 17:26:54 +0000
Mantis and Trac are both bug tracking systems. A bug tracking system is a software application that is designed to help quality assurance and programmers keep track of reported software bugs in their work. It may be regarded as a sort of issue tracking system (Wikipedia). In this article we will use Trac's alias for an issue: Ticket.

Recently I decided to replace Mantis installation used for one of my customers into Trac. Mantis worked pretty well until the date, but had missing features when compared to Trac:
- Trac supports Wiki syntax both in standalone wiki pages and inside tasks and comments
- Trac's reports and queries are superb! You can easily create custom views of Your tickets and even place it inside Your Wiki pages! Wow!
- Has integration with many version control systems - I'm going to use git integration (existing GIT-based projects)
On the other hand Mantis has some benefits over Trac:
- Comments could be edited after adding (sometimes I need to update my comment, to clarify it for instance)
- Authorisation is configurable (you can restricts access even to single comment)
- You can disable e-mail notifications about Your actions (Trac sends everything)
Migration
First of all you have to create Your Trac project:
$ trac-admin /path/to/myproject initenv
Trac supports importing Mantis database by using this script. There are few small defects in import script so execution is not straightforward (you have to change current directory to Trac project directory):
$ cd <trac-project-directory>
$ python ../mantis2trac.py --clean --db <mysql-mantis-database> --tracenv ./ -u <mysql-user> -p<mysql-password>
And finally you have to deploy Trac somewhere. Trac supports the following deployment methods:
- standalone server
- mod_python (Apache)
- cgi
- fastcgi
- mod_wsgi
I selected FastCgi (as it's two times faster than CGI and less web-server dependant than mod_python):
$ trac-admin /path/to/env deploy /path/to/www/trac
Happy Tracking!
Fri, 09 Oct 2009 17:31:10 +0000
This article shows techniques used to trim memory usage on OpenVZ system (with 128 MB RAM burstable). Mostly inspired by this article from lowendbox.com.
Minimal Debian Lenny install (33MB used):
# ps xo vsz,rsz,ucmd
VSZ RSZ CMD
1980 692 init
26988 1236 rsyslogd
5272 1024 sshd
2036 792 cron
8016 2916 sshd
4324 1632 bash
3604 804 ps
# free -m
total used free shared buffers cached
Mem: 128 33 95 0 0 0
-/+ buffers/cache: 33 95
Swap: 0 0 0
After setting "ulimit -s 128" in /etc/init.d/rc (9MB used):
# ps xo vsz,rsz,ucmd
VSZ RSZ CMD
1980 692 init
2744 1188 rsyslogd
5272 1020 sshd
2036 792 cron
8016 2888 sshd
4324 1628 bash
3604 804 ps
# free -m
total used free shared buffers cached
Mem: 128 9 118 0 0 0
-/+ buffers/cache: 9 118
Swap: 0 0 0
Next operation: replace rsyslogd with syslog-ng (still 9 MB used):
# ps xo vsz,rsz,ucmd
VSZ RSZ CMD
1980 688 init
5272 1040 sshd
2036 792 cron
2848 748 syslog-ng
8016 2892 sshd
4360 1712 bash
3604 808 ps
# free -m
total used free shared buffers cached
Mem: 128 9 118 0 0 0
-/+ buffers/cache: 9 118
Swap: 0 0 0
I replaced bash with dash (smaller memory usage). Free memory remains the same (we keep bash for root interactive login). Bigger benefits come from using dropbear instead of sshd:
# ps xo vsz,rsz,ucmd
VSZ RSZ CMD
1980 688 init
2036 792 cron
2848 748 syslog-ng
2040 468 dropbear
2700 1240 dropbear
2788 1512 bash
2084 704 ps
# free -m
total used free shared buffers cached
Mem: 128 4 123 0 0 0
-/+ buffers/cache: 4 123
Swap: 0 0 0
Yes! we're using only 4MB of VSZ now!.
Next, we would like to install a database, MySQL is a most popular choice here:
# ps xao vsz,rsz,ucmd
VSZ RSZ CMD
1980 688 init
2036 792 cron
2848 808 syslog-ng
2040 468 dropbear
2700 1332 dropbear
2796 1564 bash
1704 516 mysqld_safe
62440 17968 mysqld
1628 532 logger
2084 700 ps
# free -m
total used free shared buffers cached
Mem: 128 61 66 0 0 0
-/+ buffers/cache: 61 66
Swap: 0 0 0
Pretty fat. Let's remove innodb support first:
# ps xao vsz,rsz,ucmd
VSZ RSZ CMD
1980 688 init
2036 792 cron
2848 808 syslog-ng
2040 468 dropbear
2700 1332 dropbear
2804 1572 bash
1704 516 mysqld_safe
44648 7208 mysqld
1628 532 logger
2084 700 ps
# free -m
total used free shared buffers cached
Mem: 128 43 84 0 0 0
-/+ buffers/cache: 43 84
Swap: 0 0 0
After applying minimal settings on my.conf file:
# ps xao vsz,rsz,ucmd
VSZ RSZ CMD
1980 688 init
2036 792 cron
2848 808 syslog-ng
2040 468 dropbear
2700 1332 dropbear
2804 1572 bash
1704 516 mysqld_safe
28256 5320 mysqld
1628 532 logger
2084 708 ps
# free -m
total used free shared buffers cached
Mem: 128 27 100 0 0 0
-/+ buffers/cache: 27 100
Swap: 0 0 0
Now lightpd installation:
# ps xao vsz,rsz,ucmd
VSZ RSZ CMD
1980 688 init
2036 792 cron
2848 808 syslog-ng
2040 468 dropbear
2700 1332 dropbear
2804 1572 bash
1704 516 mysqld_safe
28256 5320 mysqld
1628 532 logger
1764 512 portmap
3136 504 famd
5408 1004 lighttpd
2084 704 ps
# free -m
total used free shared buffers cachedMem: 128 28 99 0 0 0
-/+ buffers/cache: 28 99
Swap: 0 0 0
Not bad. 28 MB used so far.
UPDATE: I found interesting article on optimizing MySQL and added the following options:
query_cache_size = 50K
query_cache_limit = 50K
Memory usage after change:
# ps xao vsz,rsz,ucmd
VSZ RSZ CMD
1980 688 init
1764 512 portmap
2796 1248 rsyslogd
5404 1008 lighttpd
3136 500 famd
2036 796 cron
2040 468 dropbear
2696 1340 dropbear
2804 1576 bash
1704 516 mysqld_safe
11436 5112 mysqld
1628 532 logger
2084 700 ps
# free -m
total used free shared buffers cached
Mem: 128 12 115 0 0 0
-/+ buffers/cache: 12 115
Swap: 0 0 0
12 MB VSZ with lightpd and MySQL! :-)
Fri, 09 Oct 2009 20:25:30 +0000
Do you want to see man pages in colors? I found this recipe:
export LESS_TERMCAP_mb=$'\E[01;31m'
export LESS_TERMCAP_md=$'\E[01;31m'
export LESS_TERMCAP_me=$'\E[0m'
export LESS_TERMCAP_se=$'\E[0m'
export LESS_TERMCAP_so=$'\E[01;44;33m'
export LESS_TERMCAP_ue=$'\E[0m'
export LESS_TERMCAP_us=$'\E[01;32m'
Here's the result:

Enjoy!
Wed, 06 Jan 2010 22:46:44 +0000
Sometimes your server responds very slowly. If you are sure it's not a networking problem (no packet loss on traceroute) you have to check other resources that may influence performance: CPU and IO.
CPU is pretty easy to check: simply run top and sort list by CPU usage (P key):

IO bottlenecks are harder to find. You can install tool names iotop (apt-get install iotop) and see which processes consume your IO. In my case (old stable kernel) I got the following error on iotop run:
# iotop
Could not run iotop as some of the requirements are not met:
- Python >= 2.5 for AF_NETLINK support: Found
- Linux >= 2.6.20 with I/O accounting support: Not found
# uname -r
2.6.18.8-linode19
Ops. There's alternative and more portable way to see which processes may be our suspects. It's D state:
# man ps
(...)
D Uninterruptible sleep (usually IO)
Simply watch output of this command:
watch -n 1 "(ps aux | awk '\$8 ~ /D|R/ { print \$0 }')"
and your suspects (processes in D state) will be visible. Also you will see current process in R state (running, use CPU).
Happy hunting!
Fri, 12 Feb 2010 22:42:58 +0000
Recently I've registered an account on twitterfeed.com site that forwards blog RSS-es to Twitter and Facebook accounts. Headers of incoming mail attracted my attention:
Return-Path: root@mentiaa1.memset.net
(...)
Received: from mentiaa1.memset.net (mentiaa1.memset.net [89.200.137.108])
by mx.google.com with ESMTP id 11si7984998ywh.80.2010.02.12.06.24.18;
(...)
Received: (from root@localhost)
by mentiaa1.memset.net (8.13.8/8.13.8/Submit) id o1CERcGq004355;
(...)
From: noreply@twitterfeed.com
(...)
Interesting parts are bolded out. As you can see registering e-mail was sent from root account. Probably the same user id is used for WWW application. That means if you break the WWW application you can gain control over whole server.
The preferred way to implement WWW services is to use account that has low privileges (www-data in Debian) because breaking the service will not threat whole server.

Sat, 27 Mar 2010 13:58:09 +0000
In Agile world there are no immutable constraints. Your requirements may change, libraries used may be replaced during development, application may outgrown your current server setup etc. I'll show you how to make web application migration between servers as fast as possible: with minimum downtime and data consistency preserved (techniques also apply to hosting providers environment).

Known Problems
You may say: moving a site? No problem: just copy your files, database and voila! Not so fast. There are many quirks you may want to handle properly:
- DNS propagation time
- Database consistency
- Preserve logs
- Preserve external system configuration
- Environment change impact integration tests
DNS Propagation Time
DNS is a distributed database handed by servers along the globe. In order to be efficient some kind of caching had to be introduced. For every DNS record you can define so called "TTL": "Time To Leave" (time in seconds when the information can be cached safely). Typical it's half hour. I suggest you to make TTL shorter (5 minutes for example) during transition.
Then create new site under new temporary address and validate if it's working properly. I suggest to configure temporary.address.com in your DNS and redirect it to your new location. This way you can access new site and validate if all is working properly under new address.
Setup redirection on old site. This redirection will work during DNS update time. Here's example that can be used for Apache (place it in .htaccess if AllowOverride is enabled):
Redirect 301 / http://temporary.address.com
Here's the poor-mans' version that use HTML HTTP-EQUIV header (use it if you don't have .htaccess enabled on your account):
<meta HTTP-EQUIV="REFRESH" content="0; url=http://temporary.address.com">
This will redirect all visitors that open your site in transition period. After it ends add redirect in opposite way: from temporary address to main application address.
Database Consistency
The worst thing you can do is to leave two public versions of your application and leave them "open" for customers. You will end up with two separate databases modifications that will result in data loss (it's practically impossible to merge updates from two databases). I suggest the following procedure:
- Setup new site under temporary address (see previous section)
- Prepare fully automated script that on new site (easy with SSH + RSA keys + Bash):
- block both application instances (service message)
- download database dump from old site
- install database dump on new site
- unblock old site and redirect to temporary adress
- unblock new site
- Test the script (only 2, 3 steps)
- Run the script
- Reconfigure DNS-es
Above procedure ensures:
- no concurrent DB state modifications (only one public version available)
- no updates lost (freeze during move)
- minimum downtime (process is automated)
Preserve Logs
Application logs hold information on application history. They are not critical to application but you may want to move them with application in order to leave historic information for analysis.
Logs could be transferred in the same step as application database. Then new location will just append to transferred logs and all history is preserved.
Preserve External System Configuration
To be checked/migrated (listed in random order).
- Webserver configuration (i.e. virtuals setup)
- Crontab setup that supports the application
- Mail Agent configuration (specific to application being moved)
Environment Change Impact Integration Tests
Your new environment may differ in environment setup to old one. That's why temporary DNS address is very useful here. You can make integration test on new location before migration to be sure no environment changes will break application. The following environment attributes need to be taken into account:
- OS architecture (32 / 64 bit)
- OS (i.e. Debian, Centos)
- Webserver software used (Apache / Lighttpd / Ngnix)
- Database versions
- Application server (JBoss, Weblogic or just plain Tomcat?)
Are there other issues I haven't mentioned?
Thu, 22 Apr 2010 10:01:13 +0000
In order to use modern Linux distributions you don't have to look at console window. All important system properties are configurable by GUI tools. There are times, however, a small bit of scripting becomes very useful. In order to easilly connect GUI and console world you have to pass data between. A small tool: xclip helps in this task.
It's very easy to install the tool under Debian-based systems:
apt-get install xclip
Collect huge selection into a file (if pasting into terminal may be very slow):
xclip -o > file_name.txt
Download selected URL into /tmp/file.out:
URL=`xclip -o`; test -z "$URL" || wget -O /tmp/file.out "$URL"
Place file contents into clipboard:
xclip -i < file_path
As you can see xclip is a handy tool built with unix-style elegance in mind. Many other applications could be discovered for this tool.
Thu, 08 Jul 2010 09:13:27 +0000
Sometimes you need to make some directories available (R/W mode) to a group of developers on a Linux / Unix server. Using shell tools make this task very easy.
First, ensure all files group are switched to desired group:
find . ! -group group1 -exec chgrp group1 '{}' \;
Then +s (sticky) bit must be attached to directories to ensure group will be preserved in newly created directories:
find . -type d ! -perm -g=s -exec chmod g+s '{}' \;
Then writeability for the group should be set:
find . -type d ! -perm -g=w -exec chmod g+w '{}' \;
And finally some users must be added to the group:
adduser user1 group1
Additionally you have to set default umask to 0002 (only o+w filtered out). It's done by installing libpam-umask and adding to /etc/pam.d/common-session:
session optional pam_umask.so umask=002
That's all.
Mon, 11 Oct 2010 21:43:10 +0000
 Good software developers are lazy persons. They know that any work that can be automated should be automated. They have tools and skills to find automated (or partially automated) solution for many boring tasks. As a bonus only the most interesting tasks (that involve high creativity) remain for them. Good software developers are lazy persons. They know that any work that can be automated should be automated. They have tools and skills to find automated (or partially automated) solution for many boring tasks. As a bonus only the most interesting tasks (that involve high creativity) remain for them.
I think I'm lazy ;-). I hope it's making my software development better because I like to hire computer for additional "things" apart from typewriter and build services. If you are reading this blog probably you are doing the same. Today I'd like to focus on C++ build process example.
The problem
If you're programmer with Java background C++ may looks a bit strange. Interfaces are prepared in textual "header" files that are included by client code and are processed together with client code by a compiler, .o files are generated. At second stage linker collects all object files (.o) and generates executable (in simplest scenario). If there are missing symbols in header file compiler raises an error, if symbol is missing on linking stage linker will complain.
On recent project my team was responsible for developing a C++ library (header and library files). This C++ library will be used then by another teams to deliver final product. Functionality was defined by header files. We started development using (automated by CPPUnitLite) unit tests then first delivery was released.
When other teams started to call our library we discovered that some method implementations were missing! It's possible to build a binary with some methods undefined in *.cpp files as long as you are not calling them. When you call that method from source code linker will find undefined symbol.
I raised that problem on our daily stand-up meeting and got the following suggestion: we have to compare symbols stored in library files (*.a, implementation) with method signatures from public *.h files (specification). Looks hard?
The solution
It's not very hard. First: collect all symbols from library files, strip method arguments for easier parsing:
nm -C ./path/*.a | awk '$2=="T" { sub(/\(.*/, "", $3); print $3; } '\
| sort | uniq > $NMSYMS
Then: scan header files using some magic regular expressions and a bit of AWK programming language:
$1 == "class" {
gsub(/:/, "", $2)
CLASS=$2
}
/^ *}/ {
CLASS = ""
}
/\/\*/,/\*\// {
next
}
buffer {
buffer = buffer " " $0
if (/;/) {
print_func(buffer)
buffer = ""
}
next
}
function print_func(s) {
if (s ~ /= *0 *;/) {
# pure virtual function - skip
return
}
if (s ~ /{ *}/) {
# inline method - skip
return
}
sub(/ *\(.*/, "", s);
gsub(/\t/, "", s)
gsub(/^ */, "", s);
gsub(/ *[^ ][^ ]* */, "", s);
print CLASS "::" s
}
CLASS && /[a-zA-Z0-9] *\(/ && !/^ *\/\// && !/= *0/ && !/{$/ && !/\/\// {
if (!/;/) {
buffer = $0;
next;
}
print_func($0)
}
Then make above script work:
awk -f scripts/scan-headers.awk api/headers/*.h | sort | uniq > $HSYMS
Now we have two files with sorted symbols that looks like those entries:
ClassName::methodName1
ClassName2::~ClassName2
Let's check if there are methods that are undefined:
diff $HSYMS $NMSYMS | grep '^<'
You will see all found cases. Voila!
Limitations
Of course, selected soultion has some limitations:
- header files are parsed by regexp, fancy syntax (preprocessor tricks) will make it unusable
- argument types (that count in method signature) are simply ignored
but having any results are better that have no analysis tool in place IMHO.
I found very interesting case by using this tool: an implementation for one method was defined in *.cpp file but resulting *.o file was merged into private *.a library. This way public *.a library has still this method missing! It's good to find such bug before customer do.
Conclusions
I spent over one hour on developing this micro tool, but saved many hours of manual analysis of source code and expected many bug reports (it's very easy to miss something when codebase is big).
Fri, 29 Oct 2010 21:27:53 +0000
 Sometimes you have to update many files at once. If you are using an IDE there is option during replace "search in all files". I'll show you how make those massive changes faster, using just Linux command line. Place this file in ~/bin/repl Sometimes you have to update many files at once. If you are using an IDE there is option during replace "search in all files". I'll show you how make those massive changes faster, using just Linux command line. Place this file in ~/bin/repl
#!/bin/sh
PATTERN="$1"
FROM="$2"
TO="$3"
FILES=$(grep -le "$FROM" `find . -name "$PATTERN"`)
echo Files: $FILES
sed -i "s!$FROM!$TO!g" $FILES
Sample usage is:
repl "*.cpp" "loadFiles" "retrieveFiles"
Some explanation about script:
- grep -l: shows on stdout only filenames of matching files
- grep -e: accepts pattern as argument
- sed -i: changing files "in place"
- grep -le: we want only files that will match $FROM to be updated (minimizes build time after change)
Pretty easy and powerful. Enjoy!
Sun, 05 Dec 2010 20:54:09 +0000
Do you want to easily control different events that may occure in your system? Are you boring of looking into log files (or do you reviewing them regularly?). Here's simple method how to not miss any interesting event! Place logs on X server root!
 As you can see you can mix logs from many sources. It's "tail -f" ported to X server. Here's command line invocation I placed in ~/.xinitrc: As you can see you can mix logs from many sources. It's "tail -f" ported to X server. Here's command line invocation I placed in ~/.xinitrc:
root-tail -color white -font "-misc-*-*-r-*-*-10-*-*-*-*-*-*-*"\
-g 2020x350+1-10 \
--outline --minspace \
~/procmail.log \
/var/log/messages \
/var/log/daemon.log \
/var/log/syslog \
~/.xsession-errors \
&
Pretty useful small pgm. Enjoy!
Thu, 09 Dec 2010 23:44:49 +0000
 Sometimes brand-new 64 bit architecture must be used for running 32-bit programs. You can preserve your 64-bit system and create so called "32 bit chroot" environment. I'll use Debian as guest operating system because it supports easy bootstrapping out-of-the-box. Sometimes brand-new 64 bit architecture must be used for running 32-bit programs. You can preserve your 64-bit system and create so called "32 bit chroot" environment. I'll use Debian as guest operating system because it supports easy bootstrapping out-of-the-box.
I assume debootstrap program is already installed. First: create Debian tree:
# debootstrap --arch=i386 lenny /home/dccb/lenny
Then we can chroot to new env and customize:
# chroot /home/dccb/lenny /usr/bin/i386
(...)
Note that shell "/usr/bin/i386" is required for chrooted environment to see 32-bit architecture. If you want to jump directly into plain user account use this command:
# chroot /home/dccb/lenny /usr/bin/i386 su - $CHROOT_USER
Inside chroot you can do (almost) everything (install programs, run daemons, ...). Note that sometimes you will have to change services ports to not collide with services present on host (HTTP, SSH, ...) - it's not a virtualisation, just chroot jail.
Additional note: In order to get correct /dev and /proc tree you have to mount them before chrootting:
mount -o bind /proc /home/dccb/lenny/proc
mount -o bind /dev /home/dccb/lenny/dev
Tue, 21 Dec 2010 22:33:23 +0000
 Recently I've been working on simple continuous integration tool that builds fresh checkouts from Perforce and uploads binary artifacts to external FTP server for testing purposes. I'm using chrooted Debian Squeeze 32 bit environment inside 64 bit host based on RPM distro (basic chroot, a simpler form of BSD's chroot jail). Recently I've been working on simple continuous integration tool that builds fresh checkouts from Perforce and uploads binary artifacts to external FTP server for testing purposes. I'm using chrooted Debian Squeeze 32 bit environment inside 64 bit host based on RPM distro (basic chroot, a simpler form of BSD's chroot jail).
The frequent problem was failing builds caused by partial commits from different teams (client was not comfortable with shared codebase ownership idea). We decided to replace rule "before every commit check if all suite is building" to "minimize failed build time as possible". How to minize the problem if it cannot be avoided at all?
The simplest answer is: notify about build problems as soon as possible. Everyone will see an e-mail with latest committer and exact build error cause. Sounds simple? Let's implement it!
The main problem with sendind out e-mails from chroot-ed env is that typically SMTP daemon is not running in the same chroot-ed environment, so locally working e-mail tools (/usr/sbin/sendmail -t) probably will not work correctly. You have to use SMTP protocol to connect to host services (not very easy from shell scripts).
sSMTP is a simple proxy that can feed locally delived content (stdin) to remote SMTP server (smarthost). In our case SMTP daemon running on host will be used. Here's my configuration for sSMTP:
# cat /etc/ssmtp/ssmtp.conf
root=me@mydomain.com
mailhub=localhost
hostname=mydomain.com
FromLineOverride=YES
ssmtp can mimic /usr/sbin/sendmail binary usage, so probably your script will not change after switching to sSMTP. And here's the sample result (generated e-mail body):
Build CL162394 failed.
Whole log: ftp://SERVER_IP/SDK/rootfs/build-dev-162394.log
Last build lines:
In file included from /usr/local/(...)
xyz.h:181: error: 'ODPlaybackState' does not name a type
(...)
make: *** [sub-CoreApplications-make_default-ordered] Error 2
UI BUILD FAILURE, ABORT
Mon, 31 Jan 2011 22:53:42 +0000

Maildir and mbox are two formats for storing e-mails locally. Both have strengths and disadvantages. If you want to convert all your mail from Maildir format to old, good mbox just issue the following script:
for a in .??*; do
echo $a
mb=${a/\./}
for msg in $a/new/* $a/cur/*; do
formail <$msg >>$mbs
done
done
You may ask: why revert to older, less flexible format? The answer is: speed (mbox is faster for many small messages).
Thu, 10 Feb 2011 22:24:10 +0000
Sometimes I would like to watch my favourite movies on my cell phone during a trip (I recommend this movie for beginners). Some phones, however, will not allow you to watch flv directly (video format supported by youtube Flash player). Also you will have problems with directly rendering Xvid/DivX format. A conversion is needed.

I'm using simple script that checks for new files in one directory, converts to suitable format and moves the file to another directory. The process is fully automated and starts on system shutdown (conversion will take some time). Any errors during conversion will be reported by e-mail using local delivery (Postfix, BTW).
#!/bin/sh
SRC=$1
DST=$2
for a in $SRC/*
do
if ! test -f "$a"
then
exit 0
fi
base=`basename "$a"`
out="$DST/$base.mp4"
if test -f "$out"
then
continue
fi
echo "Processing $a -> $out"
if nice ffmpeg -threads 2 -i "$a" -f mp4 -vcodec mpeg4 -b 250000 \
-r 15 -s 320x200 -acodec libfaac -ar 24000 -ab 64000 -ac 2 "$out" \
2> /tmp/stderr.txt
then
rm "$a"
else
rm "$out"
cat /tmp/stderr.txt | mail $LOGNAME -s "Conversion of $a failed"
fi
done
Additionally you have to install some packages in your OS:
# apt-get install ffmpeg
Sat, 12 Feb 2011 11:15:17 +0000
 I don't like when computer limits my performance. When some "manual" process is slower that my thinking process it's a very frustrating situation. That's why I love command line and keyboard shortcuts (versus GUI and mouse based interfaces). I don't like when computer limits my performance. When some "manual" process is slower that my thinking process it's a very frustrating situation. That's why I love command line and keyboard shortcuts (versus GUI and mouse based interfaces).
Under Linux we have readline library that implements command line editing with history and many other useful features.
First: allow to effectively search history by prefix (just enter some text and pressing UP/DOWN keys to select commands starting with that string):
~/.inputrc
"\e[A":history-search-backward
"\e[B":history-search-forward
Then some shortcuts that may be useful (I assume you have at least cursor keys on your terminal, so filtering them out from full list):
- Moving around
- CTRL+a: beginning of line
- CTRL+b: end of line
- ALT+b: one word left
- ALT+f: one word right
- Copy/Paste
- CTRL+k: cut to end of line
- CTRL+u: cut to beginning of line
- CTRL+w: delete word
- CTRL+y: paste at cursor position ("yank" in Emacs terminology)
- Completion
- TAB: complete current text (bash uses filesystem contents here)
Sun, 20 Feb 2011 23:55:41 +0000
Want to easily track list of processes with hierarchy on your linux box? Nothing easiest unless you don't know about few very useful "ps" command line switches. Here they are:
- "x": show also processes without TTY attached (running in background)
- "f": ascii-art process hierarchy
And a sample from my box that builds some interesting (at least for me) stuff (lines shortened slightly):
$ ps xf
PID TTY STAT TIME COMMAND
21618 ? S 0:00 su - dccb
21621 ? S 0:00 \_ -su
4460 ? R+ 0:00 \_ ps xf
28962 ? S 0:00 sh daemon-dev.sh
28963 ? S 0:00 \_ sh ../utils/create_mw_ui_rootfs_drop.sh full daemon-dev.sh
7465 ? S 0:00 \_ make
28756 ? S 0:00 \_ /bin/sh -c cd src/libs/dtvservice/ && make -f Makefile
28757 ? S 0:00 \_ make -f Makefile
3895 ? S 0:00 \_ sh4-oe-linux-g++ -c -pipe -isystem /usr/local/dcc-0.9/sh4/v
3896 ? R 0:00 \_ /usr/local/dcc-0.9/sh4/vip1960/bin/../libexec/gcc/sh4-o
3920 ? S 0:00 \_ /usr/local/dcc-0.9/sh4/vip1960/bin/../lib/gcc/sh4-oe-li
17341 ? S 0:00 sh daemon-RELEASE_0.9_branch.sh
16644 ? S 0:00 \_ sleep 5m
15554 ? S 0:00 sh daemon-RELEASE_0.10_branch.sh
16743 ? S 0:00 \_ sleep 5m
13448 ? S 0:00 sh daemon-master.sh
31613 ? S 0:00 \_ sh ../build.sh full daemon-master.sh ns4012uc
411 ? S 0:00 \_ make
637 ? S 0:00 \_ /bin/sh -c . /usr/local/dcc/mipsel/ns4012uc/env.sh; make -C api all
638 ? S 0:00 \_ make -C api all
2839 ? S 0:00 \_ make -C src/hal
7442 ? S 0:00 \_ make -C hal
4159 ? S 0:00 \_ mipsel-oe-linux-uclibc-g++ -MMD -fPIC -DPIC -isyste
4162 ? R 0:00 \_ /opt/toolchains/crosstools_hf-linux-2.6.18.0_gc
4165 ? S 0:00 \_ /opt/toolchains/crosstools_hf-linux-2.6.18.0_gc
5414 ? S 0:00 sh daemon-int-0.11.sh
8067 ? S 0:00 \_ sh ../utils/create_mw_ui_rootfs_drop.sh full daemon-int-0.11.sh /home/dccb/
21950 ? S 0:00 \_ make
1309 ? S 0:00 \_ /bin/sh -c cd CoreApplications/ && make -f Makefile
1310 ? S 0:00 \_ make -f Makefile
4396 ? S 0:00 \_ /bin/sh -c cd PVRPlayback/ && make -f Makefile
4433 ? S 0:00 \_ make -f Makefile
Mon, 07 Mar 2011 22:49:34 +0000
I'm big mutt fan. Mutt is console-based e-mail client that is very customisable. You can redefine almost everything!
Here's very useful macro that allows you to search for next e-mail in TODO state (marked with "F", "N"ew or "O"ld state). It's working in pager and index mode:
~/.muttrc
----------------
macro index . <search>~F|~N|~O<Enter><Enter>
macro pager . i<search>~F|~N|~O<Enter><Enter>
macro index , <search-reverse>~F|~N|~O<Enter><Enter>
macro pager , i<search-reverse>~F|~N|~O<Enter><Enter>

I assigned this macro to "." and "," keys that is normally not used in default mutt configuration. It allows me to reach not-yet-processed e-mails easily (".": next, "," for previous e-mail).
Thu, 24 Mar 2011 10:22:44 +0000
In order to switch X11 keyboard layout you needn't restart your X server. Just issue:
setxkbmap <language_code>
and that's all.

Thu, 07 Apr 2011 10:12:10 +0000
 Sometimes you want to avoid running second instance of some shell script. Locking implementation is not very hard: Sometimes you want to avoid running second instance of some shell script. Locking implementation is not very hard:
LOCK_FILE=$0.lock
test -f $LOCK_FILE && {
PID=`cat $LOCK_FILE`
echo "$LOCK_FILE exists, PID=$PID, exiting"
exit 1
}
echo $$ > $LOCK_FILE
trap "rm $LOCK_FILE" 0 2 3 15
Tue, 17 May 2011 21:03:21 +0000
 Almost every remote server I'm using has password login disabled. Only SSH public key login is allowed. Thus installing new public keys on server to authorize access is very frequent operation. Here's small script that allows to install public key on desired server: Almost every remote server I'm using has password login disabled. Only SSH public key login is allowed. Thus installing new public keys on server to authorize access is very frequent operation. Here's small script that allows to install public key on desired server:
#!/bin/sh
test "$2" || {
echo "usage: $0 public_key_filename host"
exit 1
}
KEY="$1"
HOST="$2"
cat $KEY | ssh $HOST "mkdir -p ~/.ssh; cat >> ~/.ssh/authorized_keys"
Small bit of scripting, but makes life much easier.
Wed, 25 May 2011 13:57:04 +0000
 Since few months I'm responsible for managing build server that perfrorms regular builds for testing purposes. Sometimes I need to stop whole build job on server (probably composed of many processes). On Linux when parent process is killed all childen are not affected and are reallocated to init (PID=1) process. I'd like to stop them as well. Since few months I'm responsible for managing build server that perfrorms regular builds for testing purposes. Sometimes I need to stop whole build job on server (probably composed of many processes). On Linux when parent process is killed all childen are not affected and are reallocated to init (PID=1) process. I'd like to stop them as well.
You can of course list process with hierarchy and kill processes manually:
ps xf
kill ... ...
But there's faster, automated, metod.
In order to kill process (given by $PID) and all subprocesses easilly you can use the following command:
kill $(ps -o pid= -s $(ps -o sess --no-heading --pid $PID))
Update 2011-12-17: there's alternative way to kill whole subtree that might be more accurate and depends on "ps xf" output:
ps xf | awk -v PID=$PID '
$1 == PID { P = $1; next }
P && /_/ { P = P " " $1; K=P }
P && !/_/ { P="" }
END { print "kill " K }'\
| sh -x
Tue, 26 Jul 2011 21:55:37 +0000
Collecting runtime errors (crashes, failed assertions, ...) is very important part of software quality efforts. If you know crash details from your testing team you can handle them even before a tester writes first line of error report (!). That improves development speed.

Probably the fastest method how to create KISS (Keep It Simple Stupid) central crash report repository is to use:
- netcat - command line UDP server
- crontab - for daily logs rotation
Let's see the crontab entry:
0 0 * * * killall -9 -q netcat; while true; do echo "A"; sleep 0.1; done | netcat -v -k -u -l 4000 \
>> crash/crash-`date +%Y%m%d`.log 2>&1 &
/dev/zero as input needed for some reason (otherwise process will exit after first crash report). "date"/"kill" allows to split crash reports per day. "-l 4000" is the port definition, "-u" tells netcat to use UDP instead of TCP (the default).
Crash handlers inside tested programs must open UDP connection to above server and send textual representation of stacktrace (should be available in rutime via reflection).
And sample result from log file (C++, but one may consider Java/Python as implementation language):
Connection from 192.168.4.168 port 4000 [udp/*] accepted
stack trace (libstacktrace init) for process /bin/busybox (PID:1342, VER=master:0f9cc45:vip1963):
(PID:1342) /usr/local/lib/libbacktrace.so : install_handler()+0x198
(PID:1342) /usr/local/lib/libbacktrace.so [0x29589e78]: ??
(PID:1342) /usr/local/lib/libbacktrace.so [0x2958db6a]: ??
stack trace END (PID:1342)
Fri, 16 Sep 2011 22:52:07 +0000
Current project I'm working on benefits from automated test suite run on few Linux-based devices. Tests are running 24x7, but sometimes device hangs (reason is still under investigation) and SSH access is blocked then.
In order to track the problem I redirected syslog (busybox-based, BTW) via network and added local automatic monitoring service that will show me when a part of my test installation go down.
The script is really simple and uses GNOME notification tool called notify-send.
#!/bin/sh
if ! ping -q -c 1 google.com > /dev/null
then
# no network present
exit
fi
for machine
do
F=/tmp/$machine
F2=/tmp/$machine.previous
if ssh $machine 'echo OK' >$F 2>&1
then
rm -f $F $F2
else
if test -f $F2
then
notify-send "$machine is not present: `cat $F`"
fi
mv $F $F2
fi
done
Details:
- I'm checking if network is available in general (google ping)
- List of SSH machines given on command line
- I assume SSH keys are setup - no password prompt
- Check state is held in /tmp/ directory
Script is started periodically from crontab:
* 9-17 * * 1-5 srv-monitor-ssh alfa beta delta zeus zeus2
and reports failure on second failed check.
Wed, 21 Sep 2011 07:09:28 +0000
 The simplest way to monitor free disk space on Linux serwer, just place it in crontab: The simplest way to monitor free disk space on Linux serwer, just place it in crontab:
0 8 * * * df -h | awk '/^\// && $5 > 95 { print "missing space", $0 }'
and ensure e-mail to this user is forwarded to you then you will see e-mail when occupied space is higher than 95% on any disk.
Pretty simple.
Thu, 08 Dec 2011 21:52:49 +0000
 Sometimes you want your user-level program to be automatically started on every Linux reboot. Scared of complicated SYSV startup scripts? Don't panic, this task is easier than you think! Sometimes you want your user-level program to be automatically started on every Linux reboot. Scared of complicated SYSV startup scripts? Don't panic, this task is easier than you think!
First of all you need root access on a machine to install startup script. Default startup scripts are placed in /etc/init.d directory and special symbolic link must be created under /etc/rc5.d (at least on Debian-based systems).
First let's create startup script for your "daemon"-like program:
/etc/init.d/myprogram:
----------------------
#! /bin/sh
PATH=/sbin:/bin
case "$1" in
start)
su -c /home/darek/bin/myprogram.sh darek &
;;
restart|reload|force-reload)
killall myprogram.sh
su -c /home/darek/bin/myprogram.sh darek &
;;
stop)
killall myprogram.sh
;;
*)
echo "Usage: $0 start|stop" >&2
exit 3
;;
esac
Note that "darek" is the user id that will be used for starting up the script.
Then: ensure it's executable and create symbolic link for default runlevel (5 on Debian):
chmod +x /etc/init.d/myprogram
cd /etc/rc5.d
ln -s ../init.d/myprogram S80myprogram
"S" means "start", "80" allows to ordered execution. Pretty simple!
SYSV init scripts are harded to setup than BSD-style, but are more flexible and easier to manage by installation tools (dpkg under Debian).
Wed, 18 Jan 2012 13:29:56 +0000
Sometimes you want to separate old files (for example older than 30 days) into separate subdirectory to make navigation easier. Using Linux tools it's pretty easy task:
mkdir -p OLD; find . -maxdepth 1 -mtime +30 -exec mv \{\} OLD \;
Explanation:
- mkdir -p OLD: create OLD subdirectory if not exists
- -maxdepth 1: search only one level under current working directory
- -mtime +30: find only files that are older than 30 days
- -exec .... \;: for every file/directory found execute the following command
- \{\}: will be replaced by filename
Above command will move all old files/subdirectories into OLD subdirectory.
Sat, 25 Feb 2012 13:34:11 +0000
 Locate duplicates quickly: I mean only size+filename check, not expensive MD5 sum computation: Locate duplicates quickly: I mean only size+filename check, not expensive MD5 sum computation:
find . -printf "%f:%s:%p\n" -type f | \
awk -F: '
{
key=$1 " " $2;
occur[key]++;
loc[key]=loc[key] $3 " "
}
END {
for(key in occur) {
if(occur[key]>1) {
print key ": " loc[key]
}
}
}
' | sort
A bit of explanation of above magic:
- printf: tells find command to output file metadata instead of only file path (the default), this metadata (size, filename) will be used later
- -F: :We want to handle properly paths with spaces, that's why special separator is used
- key=$1 " " $2: we use file name (without dir) and file size to create ID for this file
- occur: table (key -> number of file occurences)
- loc: maps file ID to list of locations found
- occur[key]>1: we want to show only files that have duplicates
- sort: results are sorted alphabetically for easier navigation
Tue, 18 Sep 2012 19:51:34 +0000
 One of my responsibilities in current project is analysis of "hard" bugs - problems that are not easily reproducible or the cause is so mysterious that remains unresolved (or worse: resolved - not reproducible) even after few iterations developer <-> integration team. The problem visible in production environment but not reproducible by developer is pretty simple: you have to check logs carefully and match source code to derive results. Random problem with unknown exact reproduction steps but visible sometimes in PROD environment is harder - there's even no easy validation procedure for our fixes. One of my responsibilities in current project is analysis of "hard" bugs - problems that are not easily reproducible or the cause is so mysterious that remains unresolved (or worse: resolved - not reproducible) even after few iterations developer <-> integration team. The problem visible in production environment but not reproducible by developer is pretty simple: you have to check logs carefully and match source code to derive results. Random problem with unknown exact reproduction steps but visible sometimes in PROD environment is harder - there's even no easy validation procedure for our fixes.
Recently I've hit one of most mysterious problems ever seen. After some time application logs are filled by "too many jobs" error message. The source of this message was tracked to libupnp library by google lookup pretty easily.
Libupnp handles UPNP (Universal Plug And Play) protocol that is used for auto-discovery of network services (printers, streaming applications, ...). When new multicast announcement is received uPNP client downloads XML description of that service using HTTP protocol. This activity is done in newly created separate thread. Libupnp limits number of threads to 100 in order not to abuse system resources.
And here comes the problem localisation: with frequent multicast announcements and very slow (or unavailable) HTTP service it possible for libupnp to create 100 threads waiting for HTTP responses and no new threads can be created. I prooved that by:
- starting local uPNP service (mediatomb) on my laptop: service mediatomb start
- block HTTP port that serves description: iptables -A INPUT -p tcp --dport 49152 -j DROP ("DROP" prevents from sending any response, so a peer don't know what's going on)
- Generate some UPNP_* events (hello/bye): while true; do service mediatomb restart; sleep 1; done
- Watch logs
The solution seems to be very easy: lower HTTP timeout so "unavailable" uPNP devices (note the quotes, in my opinion it's a network configuration error) will not block our device. After searching in source code I located the line:
#define HTTP_DEFAULT_TIMEOUT 30
I lowered it to 2 seconds, rebuilt libupnp and did my test again. And it didn't work.
I've analysed where this timeout is applied, checked every socket API call and found the following line:
ret_code = connect( handle->sock_info.socket,
( struct sockaddr * )&peer->hostport.IPv4address,
sizeof( struct sockaddr_in ) );
note that it's a blocking call with timeout set by operating system (on Linux it depends on /proc/sys/net/ipv4/tcp_syn_retries).
So even if we apply timeouts properly when HTTP (TCP) port is open it's the port opening time that gives so big delay (>20 seconds in our case). Solution was to use non-blocking connections and select() call properly (pseudo code below):
// set non-blocking mode
fcntl(sock, F_SETFL, flags | O_NONBLOCK);
// start connecting in background
connect(sock, (struct sockaddr *)&sa, size));
// wait until connection is made or timeout is reached
ret = select(sock + 1, &rset, &wset, NULL, (timeout) ? &ts : NULL));
// put socket back in blocking mode
fcntl(sock, F_SETFL, flags);
After that change unavailable (due to network error or local firewall) devices were quickly discovered (in 2 seconds).
Thu, 15 Nov 2012 10:13:25 +0000
First question: why do you need local Debian-based install inside your Debian distro? Sometimes you want to check some experimental packages and don't want to break your base system or start some service in isolated environment without virtualisation effort. Then chroot comes as an effective solution for you!
First of all you have the debootstrap program that is used to do all the job you need:
sudo apt-get install debootstrap
Then you select your favourite distro version and download URL:
sudo debootstrap --arch i386 squeeze /home/debian-chroot http://ftp.debian.org/debian
And you jump to your newly-installed system:
sudo chroot /home/debian-chroot
And: voila! Done!
Fri, 12 Apr 2013 07:24:28 +0000
If you want to skip error sockets-related code during backup of whole filesystem you will be surprised there's no --ignore-sockets switch. But there's elegant method to to that:
cd /
sudo find . -type s > /tmp/sockets.lst
if sudo tar zcvpf $TMP_FILE --one-file-system --exclude-from=/tmp/sockets.lst -C / .
then
echo backup OK
fi
Wed, 22 May 2013 23:04:14 +0000
My current customer develops embedded devices used by many end users. In order to save server load devices use multicasts for downloading data: every device registers itself on multicast channel using IGMP and listens to UDP packets. No connections to be managed results in lower overhead.
However, some data (or some requests) cannot be downloaded from multicasts channels and HTTP/HTTPS must be used to interact with server. As the number of devices is very high special methods have been used in order not to overload backend servers (randomised delays, client software optimization).
Consequently, small bug in client software that will trigger more events than usual can be very dangerous to whole system stability (because the effect of thousands of devices - perfect DDOS may kill back-end). In order to catch such errant behaviour as soon as possible I've developed daily report that controls server usage in my customer office.
First of all, we need to locate the most "interesting" device by IP address from logs (we list top 20 IPs based on server usage):
ssh $server "cat /path-to-logs/localhost_access_log.$date.log" | awk '
{
t[$1 " " $7]++
ip[$1]++
}
END {
for(a in t) { print t[a], a }
max = 0
max_ip = ""
for(a in ip) { if(ip[a] > max) { max=ip[a]; max_ip=a; } }
print max_ip > "/tmp/max_ip"
}
' | sort -n | tail -20
IP="`cat /tmp/max_ip`"
Then selected IP will be examined hour-by-hour to locate patterns in behavior:
ssh $server "cat /path-to-logs/localhost_access_log.$date.log" | awk -v "SEARCH=$IP" '
{ sub(/:[0-9][0-9]:[0-9][0-9]$/, "", $4); TIME=$4; s[TIME]; }
$0 ~ SEARCH { s[TIME]++;}
END { for(a in s) { print a, s[a] } }
' $* | sort
Sample results with included requested URLs:
Number of calls on 2013-05-22, server: tm2
3 192.168.4.101 /path/nPVR getseries
3 192.168.4.101 /path/reminder get
3 192.168.4.101 /path/rentedItems
3 192.168.4.101 /path/stbProperties get
3 192.168.4.101 /path/subscriberInfo
3 192.168.4.140 /path/autoConfig
6 192.168.4.249 /path/authenticate
6 192.168.4.249 /path/favorite get
6 192.168.4.249 /path/rentedItems
6 192.168.4.249 /path/stbProperties get
7 192.168.4.249 /path/reminder get
7 192.168.4.249 /path/subscriberInfo
8 192.168.4.140 /path/authenticate
8 192.168.4.249 /path/nPVR get
8 192.168.4.249 /path/nPVR getseries
16 192.168.4.254 /path/subscriberInfo
25 192.168.4.254 /path/nPVR get
25 192.168.4.254 /path/nPVR getseries
83 192.168.4.254 /path/favorite get
98 192.168.4.254 /path/reminder get
192.168.4.254 activity per hour:
[22/May/2013:00
[22/May/2013:01
[22/May/2013:02
[22/May/2013:03
[22/May/2013:04
[22/May/2013:05
[22/May/2013:06
[22/May/2013:07
[22/May/2013:08
[22/May/2013:09
[22/May/2013:10
[22/May/2013:11
[22/May/2013:12 8
[22/May/2013:13 4
[22/May/2013:14 16
[22/May/2013:15 18
[22/May/2013:16 12
[22/May/2013:17 50
[22/May/2013:18 24
[22/May/2013:19 24
[22/May/2013:20 24
[22/May/2013:21 24
[22/May/2013:22 24
[22/May/2013:23 22
We can see that 192.168.4.254 device started to spam server 24 times per hour from 18:00 until midnight (imagine thousands of devices that synchronously send requests to back-end the same way). This device logs will be thoroughly examined for possible reason for that behaviour.
At Aplikacja.info, we believe that software problems must be located as early as possible (even during development process). In above example we re-use existing development environment to catch problems that might be discovered in production with huge user base.
The general idea is to move detection and neutralisation of a problem into this direction:
1. end user -> 2. customer's QA -> 3. development company's QA -> 4. developer (runtime) -> 5. developer (build time)
The more distance from end user a bug is detected and fixed the better for us. I hope you would love to squash problems the same way.
Happy hunting!
Fri, 14 Jun 2013 11:48:17 +0000
It's pretty easy to find CPU usage per process (top, ps), but If you want to find top CPU users per thread there's a method:
$ awk '{printf "TID: %6u %8u %8u %8u \t %s \n", $1, $14, $15, $14+$15, $2;}' /proc/*/task/*/stat | sort -n -k 5 | tail -10
TID: 3600 33700 11461 45161 (metacity)
TID: 3612 38053 7716 45769 (nautilus)
TID: 3634 65079 0 65079 (dconf
TID: 3601 64168 4997 69165 (gnome-panel)
TID: 17298 137525 15650 153175 (firefox)
TID: 3840 168736 21351 190087 (skype)
TID: 11622 76119 150472 226591 (multiload-apple)
TID: 3616 492076 53810 545886 (gnome-terminal)
TID: 3617 370649 220327 590976 (skype)
TID: 1072 626086 1031732 1657818 (Xorg)
Results are sorted by cumulated CPU usage (user + system).
Mon, 02 Sep 2013 06:52:59 +0000
AWK is small but very useful Unix scripting language that is mainly aimed at text files filtering and modification. If you're on embedded device you might expect bigger brothers (as Perl / Python) are not available, but AWK is usually shipped with busybox (= small).
One of missing functionalities is join() function (the opposite of splitting string by regular expression). One can implement it pretty easily, however:
function join(array, sep,
result, i)
{
if (sep == "")
sep = " "
else if (sep == SUBSEP) # magic value
sep = ""
result = array[1]
for (i = 2; i in array; i++)
result = result sep array[i]
return result
}
Usage:
split(s, arr, "|")
output = join(arr, "|")
As a result input string s will have the same contents as output. The function is useful for scripted modification of CSV files.
Mon, 16 Sep 2013 21:47:17 +0000
Just found: an interesting method to check how your NAND driver (and filesystem kernel module) behave during massive write operations. I've added additional printk-s() to NAND driver kernel module write() call and collected data during filling all available filesystem space.
Output dmesg logs have been preprocessed and offset call parameter has been presented as a graph using gnuplot (horizontally: write number, vertically: offset):
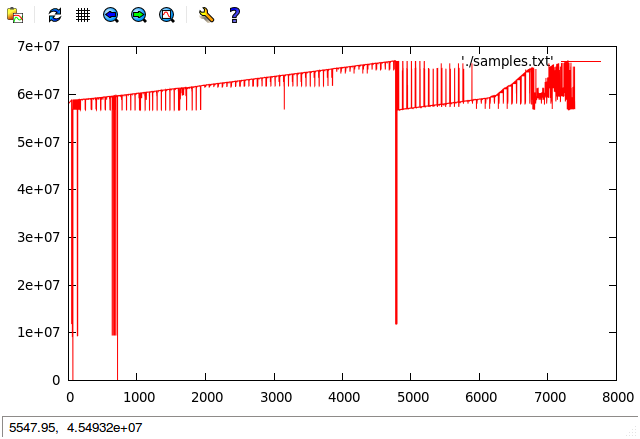
What can we see from that graph:
- some writes at offset 0 - typically dangerous as might overwrite bootloader area, I've added them intentionally in this graph by reflashing bootloader manually
- with missing space wear levelling is less efficient - right part of the graph
- we can see that catalog location (blocks with filesystem metadata) is moved dynamically across all space to avoid multiple writes to the same location (NAND specific), we see the location has been changed ~6 times during whole operation (probably relocation is done after every 2000 write operations)
- two different partitions are visible (one at ~60M, one at ~10M)
Thu, 28 Nov 2013 07:57:14 +0000
 First of all: you have to install the server (I assume you use Debian / Ubuntu): First of all: you have to install the server (I assume you use Debian / Ubuntu):
apt-get install mysql-server
Then you have to create database, user and password (for sake of simplicity, not security, name, login and password are the same):
N=<DB_NAME>; echo "create database $N; grant usage on . to $N@localhost identified by '$N'; grant all privileges on $N.* to $N@localhost ;" | mysql -u root
Then you should configure your program:
- db_name=<DB_NAME>
- db_user=<DB_NAME>
- db_password=<DB_NAME>
- host=localhost
Beware (SECURITY): I assume you have MySQL external connection closed (only local) and you trust every user from your Linux installation, they will have access to your database easily in such setup.
Fri, 29 Nov 2013 14:10:30 +0000
Sometimes you need to quickly measure current bandwidth used by your Linux box and don't have dedicated command installed. You can use standard /proc/ file entries to get that info from the system.
Example of a embedded device with a TS stream as an input:
( cat /proc/net/dev; sleep 1; cat /proc/net/dev; ) | awk '/eth0/ { b=$1; sub(/eth0:/,"",b); if(bp){ print (b-bp)/1024/1024, "MB/s" }; bp=b }'
1.00053 MB/s
Wed, 09 Apr 2014 06:02:26 +0000
Sat, 13 Sep 2014 17:22:57 +0000
Few days ago I launched simple low-traffic mailing list using naive /etc/aliases method, but got the following error:
<example1@onet.pl> (expanded from <example@myserver.com>): host
mx.poczta.onet.pl[213.180.147.146] said: 554 5.7.1 <example1@onet.pl>:=
Recipient address rejected: Spf check: fail (in reply to RCPT TO command)
If you think for a moment the reason for error it's obvious. My server tried to forward e-mail using original From address.Onet.pl checked TXT record (using SPF standard) for my server domain myserver.com and noticed it's not allowed to send e-mails from me.
In order to make things work properly one have to rewrite envelope From field properly. Mailing list managers usually do that properly (/etc/aliases is not enough).
I wanted to make minimal and fast deployment of SMTP-only mail list manager. I selected smartlist because of it's simplicity. Firstly you have to install the software:
# apt-get install smartlist
Then you have to redirect two e-mail addresses: mylist@myserver.com and mylist-request@myserver.com to smartlist program (flist):
# cat >>/etc/aliases <<EOF
mylist: "|/var/list/.bin/flist mylist"
mylist-request: "|/var/list/.bin/flist mylist-request"
EOF
newaliases
After that anyone can subscribe to the list using mylist-request@myserver.com.
If you want to initially populate mailing list (the mailing list is closed for example) it's very easy:
# su list
$ cd cd /var/list/mylist
$ cat >> dist <<EOF
abc@example.com
def@appale.com
EOF
Sat, 03 Jan 2015 17:46:10 +0000
If you are an embedded software developer like me chances are you use embedded Linux for the purpose. It's Open Source, has great tools support and is a great software environment where (almost) everything could be automated through command line interfaces.
Once you decide about operating system used the next step is to choose a build system that would be used for the task of building the software. There are few choices you can select from:
- use pre-built toolchain and rootfs and add your binaries and configuration files (i.e. STLinux for ST-based devices)
- use OpenEmbedded for full-featured buildsystem with packaging system included
- use BuildRoot for simple build system without packaging system included
Today I'm going to tell you about the 3rd option. Buildroot states their view on packaging systems for embedded development this way:
We believe that for most embedded Linux systems, binary packages are not necessary, and potentially harmful. When binary packages are used, it means that the system can be partially upgraded, which creates an enormous number of possible combinations of package versions that should be tested before doing the upgrade on the embedded device. On the other hand, by doing complete system upgrades by upgrading the entire root filesystem image at once, the image deployed to the embedded system is guaranteed to really be the one that has been tested and validated.
After few years with OpenEmbedded and few months with Buildroot I like the simplicity of Buildroot model. Below you can find basic (the most important in my opinion) concepts of Buildroot.
Buildroot uses basic "make" interface and, actually, it's written in Makefile language. It's clearly visible in (sometimes) weird syntax for packages declaration. For configuration Config.in files are used (the same as for Linux kernel configuration). It's quite useful and extensible choice for configuration and building.
Recipes system (usually placed under package/ subdirectory) describes in Makefile+Config.in language rules for fetching / configuring / building / installing. You can build+install selected package by issuing: "make <pkg-name>" - quite simple and elegant solution.
Each build is configured in .config file that could be edited make well-known "make menuconfig" interface:
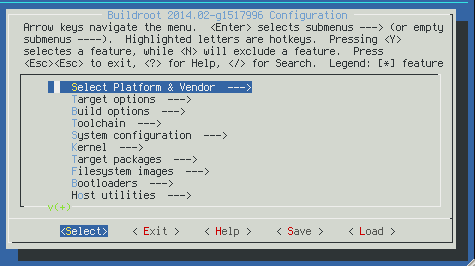
You could select build switches there as well as list of included packages.
All the output is placed under "output" subdirectory (you can force full clean by deleting this directory):
- build/<pkg-name>/ - working directory for building given package (no "rm_work" there as in OE, build directories are kept after build)
- build/<pkg-name>/.stamp_* - describes build state for given package, you can force given stage by deleting selected files there
- host/ - the toolchain
- target/ - rootfs (filled in fakeroot mode) used for creating resulting images
- images/ - resulting images are placed there (tgz, squashfs, kernel binary and so on)
Basic input directories:
- package/<pkg-name>/<pkg-name>.mk - a recipe for given package (Makefile syntax)
- Config.in - root of configuration files possible options
- dl/ - this directory is not stored in version control system, but holds cached version of downloads. It's placed outside of output directory in order not to download source packages after every clean
- fs/ - recipes for various output image options (tgz, squashfs and so on)
- system/skeleton/ - basic filesystem structure
The buildsystem is very fast and allows very high level of customizations.
Tue, 24 Feb 2015 22:22:32 +0000
 STB (Set Top Box) devices usually run from NAND partitions. All the rootfs is persisted in read-only filesystem (squashfs) and mounts additional R/W locations if needed (ramdisk for /tmp storage, at least). This setup works quite well for final deployment, but might be a bit problematic if you, actually, develop software stack and need to update and test many times per day. STB (Set Top Box) devices usually run from NAND partitions. All the rootfs is persisted in read-only filesystem (squashfs) and mounts additional R/W locations if needed (ramdisk for /tmp storage, at least). This setup works quite well for final deployment, but might be a bit problematic if you, actually, develop software stack and need to update and test many times per day.
This is the place where long-time forgotten network boot method comes to play.
In the old days (university) I remember "thin Solaris clients" that were used for programming classes. They had no hard disk and booted from network. What the boot process does look like?
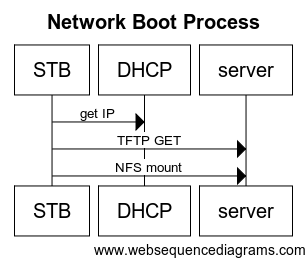 First of all: the STB bootloader must be able to use IP network, so IP address is obtained from DHCP. First of all: the STB bootloader must be able to use IP network, so IP address is obtained from DHCP.
Then kernel image is downloaded from the server using TFTP protocol and started. TFTP is a very limited file transfer protocol that is easy enough to be implemented in bootloaders.
Kernel is configured to mount NFS storage as root ("/") filesystem. Starting from this step startup scripts are executed.
What are the benefits of TFTP/NFS setup for development? You might place TFTP and NFS storage on your development machine and easily upgrade software stack and quickly test fixes. It makes no sense to build whole image all the time, incremental updates are many times faster.
Thu, 12 Nov 2015 11:29:13 +0000
When you work over serial line on an embedded device usually the terminal size it set to 80x25.
There's an easy way, however, to setup your real terminal size, just add the following line to your profile script (~/.profile):
resize > /tmp/resize
. /tmp/resize
resize command detects real terminal size and sets COLUMNS and ROWS parameters accordingly:
# resize
COLUMNS=159;LINES=52;export COLUMNS LINES;
One just need to execute the output as sh commands (using source "." command).
Thu, 12 Nov 2015 15:57:01 +0000
 In order to locate conflicting DHCP server in your LAN execute the following command: In order to locate conflicting DHCP server in your LAN execute the following command:
sudo dhcpdump -i eth4 | awk '/IP:/{SRC=$2 " " $3} /OP:.*BOOTPREPLY/{ print "DHCP server found:", SRC; }'
The restart your PC network (use DHCP to get new IP). If you see more than one IP address here:
DHCP server found: 192.168.4.1 (0:9:6b:a3:fc:4a)
DHCP server found: 192.168.1.1 (f8:d1:11:9e:1d:8b)
DHCP server found: 192.168.4.1 (0:9:6b:a3:fc:4a)
DHCP server found: 192.168.1.1 (f8:d1:11:9e:1d:8b)
DHCP server found: 192.168.4.1 (0:9:6b:a3:fc:4a)
Then you have two, conflicting DHCP servers in your network. You can use http://www.coffer.com/mac_find/ tool to locate the device type that causes the problems.
Fri, 22 Jan 2016 20:24:00 +0000
 Writing Makefiles is a complicated process. They are powerful tools and, as such, show quite high level of complexity. In order to make typical project development easier higher level tools have been raised. One of such tools is CMake. Think of CMake for Make as C/C++ compiler for assembly language. Writing Makefiles is a complicated process. They are powerful tools and, as such, show quite high level of complexity. In order to make typical project development easier higher level tools have been raised. One of such tools is CMake. Think of CMake for Make as C/C++ compiler for assembly language.
CMake transforms project description saved in CMakeLists.txt file into classical Makefile that could be run by make tool. You write your project description in a high level notation, allowing CMake to take care of the details.
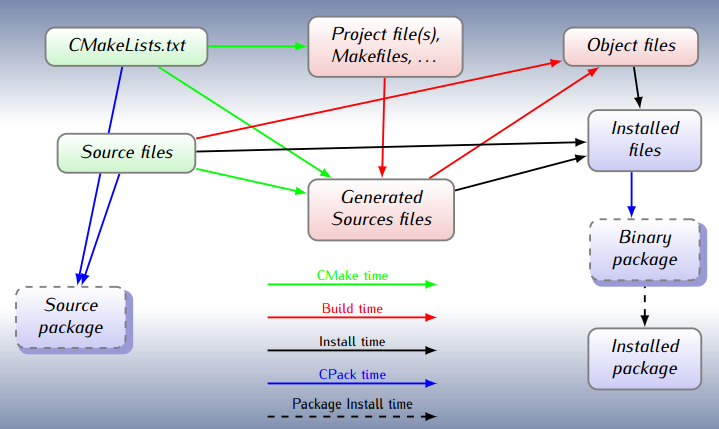
Let's setup sample single source code executable, the simplest possible way (I'll skip sample_cmake.cpp creation as it's just C++ source code with main()):
$ cat CMakeLists.txt
cmake_minimum_required(VERSION 2.8)
project (SampleCmake)
add_executable(SampleCmake sample_cmake.cpp)
Then the build:
$ cmake .
-- The C compiler identification is GNU
-- The CXX compiler identification is GNU
-- Check for working C compiler: /usr/bin/gcc
-- Check for working C compiler: /usr/bin/gcc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Configuring done
-- Generating done
-- Build files have been written to: /home/darek/src/cmake
$ make
Scanning dependencies of target SampleCmake
[100%] Building CXX object CMakeFiles/SampleCmake.dir/sample_cmake.cpp.o
Linking CXX executable SampleCmake
[100%] Built target SampleCmake
After the procedure one can find the output in current directory: SampleCmake binary (compiled for your host architecture, cross-compiling is a separate story).
More complicated example involves splitting project into separate shared library files. Let's create one in a subdirectory myLibrary/, new CMakeLists.txt there:
project (myLibrary)
add_library(MyLibrary SHARED sample_library.cpp)
Then you need to reference this library from Main CMakeLists.txt file:
add_subdirectory(myLibrary)
include_directories (myLibrary)
target_link_libraries (SampleCmake MyLibrary)
What happens there?
- myLibrary subdirectory is added to the build
- subdirectory for include files is specified
- SampleCmake binary will use MyLibrary
Let's build the stuff now:
$ cmake .
-- Configuring done
-- Generating done
-- Build files have been written to: /home/darek/src/cmake
$ make
Scanning dependencies of target MyLibrary
[ 50%] Building CXX object myLibrary/CMakeFiles/MyLibrary.dir/sample_library.cpp.o
Linking CXX shared library libMyLibrary.so
[ 50%] Built target MyLibrary
Scanning dependencies of target SampleCmake
[100%] Building CXX object CMakeFiles/SampleCmake.dir/sample_cmake.cpp.o
Linking CXX executable SampleCmake
[100%] Built target SampleCmake
Then you will get: an executable in current directory (SampleCmake) and a library in subdirectory (myLibrary/libMyLibrary.so).
Of course, some "obvious" make targets (as make clean) would work as expected. Others (make install_ might be enabled in a CMake configuration.
Interesting function (also visible in QMake) is the ability to detect changes in CMake project files and autoatically rebuild Makefiles. After 1st CMake run you don't need to run it again, just use standard make interface.

|
Tags
|

























