About This Site
Software development stuff
Archive
- 2017
- 2016
- 2015
- 2014
- 2013
- 2012
- 2011
- 2010
- 2009
- 2008
- 2007
|
Entries tagged "quality".
Thu, 22 Feb 2007 21:27:57 +0000
J2EE to w uproszczeniu zbiór technologii opartych o Javę służących do tworzenia aplikacji dostępnych przez sieć. Elastyczność i możliwość konfiguracji, oparta w głównej mierze na plikach XML, prowadzi do tego, że coraz więcej błędów znajduje się poza kontrolą kompilatora.
W systemach starszego typu większość konfiguracji interakcji pomiędzy poszczególnymi fragmentami systemu była opisana w kodzie i jako taka mogła byś sprawdzona (przynajmniej częściowo) w fazie kompilacji. Tendencja wyrzucenia części informacji poza kod Javy powoduje niestety, że uzyskując elastyczność i pozorną łatwość wprowadzania zmian wypychamy błędy do fazy uruchomienia (run time).
Złożoność architektury J2EE powoduje, że cykl pracy (rekompilacja, instalacja, testowanie w przeglądarce) jest długi. Utrudnia to znacznie usuwanie błędów metodą "popraw i przeklikaj". Co można zrobić aby przyspieszyć proces usuwania błędów w J2EE?
Weryfikacja Statyczna
Większości z nas weryfikacja statyczna oprogramowania kojarzy się z wspomaganymi komputerowo systemami dowodzenia poprawności oprogramowania. Idea jest taka, by bez uruchamiania programu wychwycić wszystkie błędy, które mogą wystąpić w systemie. Dzięki temu (teoretycznie) faza testowania tylko potwierdza, że program jest napisany prawidłowo. Jednak kryje się w tym pomyśle kilka poważnych trudności z którymi jak do tej pory nie udało się informatyce uporać:
- W praktyce napisanie formalnej specyfikacji funkcjonalności jest trudne i pracochłonne
- Narzędzia służące do weryfikacji są trudne w użyciu i wymagają długiej praktyki przez produktywnym wykorzystaniem
- Nie zawsze da się automatycznie sprawdzić formalną specyfikację względem programu automatycznie (wymagana jest interwencja człowieka)
Jak widzimy pełna weryfikacja statyczna nie jest możliwa do zastosowania w typowych systemach. Czy jednak niektórych cech systemu nie możemy sprawdzić statycznie?
Zasoby w J2EE
Przez pojęcie zasób na potrzeby niniejszego artykułu rozumiem elementy aplikacji J2EE, które można niezależnie analizować, a które są wiązane ze sobą po instalacji w serwerze aplikacyjnym. Jednym z zasobów jest np. kod Javy, analiza jest przeprowadzana przez kompilator podczas kompilacji. Poniżej wymieniam kilka wybranych "zasobów":
- Kod Javy (możliwy dostęp: wyrażenia regularne, mechanizm refleksji)
- Konfiguracja Struts (możliwy dostęp: parser SAX)
- Pliki JSP (możliwy dostęp: parser SGML)
- Konfiguracja Tiles (możliwy dostęp: parser SAX)
- Tłumaczenie w ApplicationResources_*.properties (biblioteka standardowa Javy)
- ...
Jakie korzyści możemy osiągnąć zajmując się statycznie powyższymi zasobami? Najlepiej będzie to wyjaśnić opisując typowe błędy w aplikacji J2EE, które są zwykle odkrywane dopiero na etapie uruchomienia w serwerze aplikacyjnym.
- Wyjątek na stronie spowodowany użyciem tagu html:text z wartością atrybutu property, które nie istnieje jako atrybut w form beanie
- Literówka w atrybucie action w tagu html:form, która powoduje błąd braku strony pod danym URL
- Brak tłumaczenia dla tekstu statycznego występującego na stronie w tagu bean:message
- Użycie nieprawidłowego atrybutu name w którymś ze strutsowych tagów powoduje wyjątek
Odnajdywanie tego typu błędów, zwłaszcza kiedy projekt podlega ciągłym modyfikacjom, jest zajęciem mało efektywnym i męczącym. Czy nie prościej było by dostawać pełną listę tego typu błędów w ciągu kilku sekund zamiast tracić czas testerów na takie oczywiste defekty?
Uważam, że praca testera powinna polegać na sprawdzaniu zgodności ze specyfikacją i błędy spowodowane literówkami już nie powinny pojawiać się w tej fazie. W jaki sposób możemy statycznie "wyłuskiwać" klasy błędów opisane powyżej?
- Test jednostkowy, który na podstawie tagu html:text (parser SGML-a) znajdzie form beana użytego w danym tagu i sprawdzi, czy w tym beanie istnieje atrybut określony przez property
- Poprawność użytych atrybutów action można sprawdzić porównując je ze zdefiniowanymi akcjami w pliku konfiguracyjnym Struts
- Dla każdego wystąpienia bean:message sprawdzić, czy istnieje wpis w pliku z tłumaczeniami
- Zły name oznacza odwoływanie się do beana pod nieistniejącą nazwą
Implementacje
Udało mi się zastosować powyższe techniki dla następujących konfiguracji J2EE:
- JSF: parsowanie Java i JSP w oparciu o wyrażenia regularne, parser i weryfikator w języku AWK
- Struts: parser SGML do JSP, Beany Javy dostępne poprzez mechanizm refleksji
- Hibernate: statyczna analiza parametrów zapytania w HQL-u względem beana, który zawiera parametry
Sat, 22 Mar 2008 21:27:09 +0000
Zwykle testami jednostkowymi nazywa się wszystko co jest uruchamiane z poziomu JUnit. W większości przypadków nie są to testy jednostkowe, ale testy integracyjne, których utrzymanie i wytworzenie jest znacznie trudniejsze niż testów jednostkowych. Paul Wheaton wskazuje jakie korzyści osiągamy stosując rzeczywiste testy jednostkowe.
Paul proponuje następujące definicje w stosunku do pojęć związanych z testami:
- Test jednostkowy (Unit Test)
- Test nie mający kontaktu z bazą danych, serwerem aplikacyjnym, systemem plików, inną aplikacją, konsolą, mechanizmem logowania. Sprawdza zwykle jedną wybraną metodę izolując ją od innych obiektów poprzez obiekty Mock.
- Zbiór testów regresyjnych (Regression Suite)
- Kolekcja testów która może być uruchomiona " za jednym kliknięciem"
- Test Funkcjonalny (Functional Test)
- Sprawdza wiele metod / klas.
- Test Integracyjny (Integration Test)
- Sprawdza kilka komponentów współpracujących ze sobą.
- Test Komponentu (Component Test)
- Sprawdza działanie wybranego komponentu. Nie należy do zbioru testów regresyjnych.
- Akceptacyjny Test Komponentu (Component Acceptance Test)
- Formalny proces oceny pracy komponentu przez kilka osób.
- Test Systemowy (System Test)
- Wszystkie komponenty uruchomione razem.
- Systemowy Test Akceptacyjny (System Acceptance Test)
- Formalny proces oceny pracy systemu (wszystkie komponenty połączone razem) przez kilka osób.
- Test Obciążeniowy (Stress Test)
- Sprawdzenie działania komponentu(ów) uruchomionych pod zwiększonym obciążeniem.
- (Mock)
- Obiekt "udający" inny obiekt mający na celu odseparowanie obiektu podlegającego testom od innych obiektów.
- (Shunt)
- Podobny do obiektu Mock, ale nie izolujący w całości kodu od środowiska.
Problem zbyt wielu testów funkcjonalnych
Typowym objawem korzystania z testów funkcjonalnych zamiast testów jednostkowych jest liczba testów jakie zawodzą kiedy w kodzie pojawi się błąd:
Przy prawidłowo utworzonych testach jednostkowych sytuacja będzie następująca:
Nieporozumienia na temat testów jednostkowych
- "Pisząc tylko testy jednostkowe piszą mniej kodu testowego, a sprawdzam więcej kodu produkcyjnego"
- Prawda, ale za cenę zwiększenia kruchości projektu. Także niektóre scenariusze są dużo trudniejsze do uruchomienia tylko w testach integracyjnych. Najlepsze pokrycie kodu można osiągnąć tylko poprzez odpowiednie połączenie testów jednostkowych z testami integracyjnymi.
- "Logika biznesowa opiera się na współpracujących klasach, więc testowanie klasy w odosobnieniu jest bezcelowe"
- Paul sugeruje testowanie wszystkich metod, ale oddzielnie. Zwraca uwagę, że testy integracyjne także mają swoją wartość.
- "Nie przeszkadza mi, że uruchomienie zestawu testów zajmuje kilka minut"
- Duży czas wykonania testów skłania do rzadszego uruchamiania testów i może z czasem prowadzić do zaprzestania uruchamiania testów (nikomu nie będzie sie chciało czekać na efekty).
- "Test jednostkowy to każdy test uruchomiony przez JUnit"
- Można uruchamiać testy integracyjne i systemowe korzystając z biblioteki JUnit.
Thu, 30 Jul 2009 22:48:54 +0000
W artykule Robert Mays opisuje swoje doświadczenia i sugestie związane z zapobieganiem defektom. Artykuł ukazał się w IBM Systems Journal w 1990 roku (niestety adres URL jest już nieaktualny).
Zapobieganie defektom składa się z czterech elementów włączonych w proces tworzenia oprogramowania:
- spotkania w trakcie których dokonywana jest szczegółowa analiza przyczyn (root cause) błędów i sugerowane są akcje prewencyjne
- wdrożenie akcji prewencyjnych w zespole
- spotkania przed pracą mające na celu zwrócenie uwagi programistów na sprawy jakości
- zbieranie i śledzenie danych
Autor wskazuje, że efektywniej jest zapobiegać pojawianiu się błędów niż je wyszukiwać (inspekcje, testowanie). Wtedy czas przeznaczany typowo na wyszukanie błędów można spożytkować w inny sposób (np. pracując nad kolejnym produktem).
Prewencja błędów opiera się na ciągłej analizie przyczyn błędów i usuwanie tych przyczyn poprzez poprawę procesu, metodyki pracy, technologii i narzędzi. Przy analizie przyczyn korzysta się z diagramów przyczynowo - skutkowych (czasami zwanych diagramami Ishikawy od nazwiska twórcy).
Proces ten zakłada włączenie różnych aktywności związanych z jakością do codziennej pracy zespołu.
Analiza wykrytych błędów
Podstawową aktywnością w projekcie jest spotkanie poświęcone analizie wykrytych błędów. Zespół próbuje znaleźć przyczyny (root cause) zaistniałych błędów i następnie proponuje wprowadzenie modyfikacji w procesie produkcyjnym, by zapobiec powstaniu takich błędów w porzyszłości. Dla każdego błędu stawiane są następujące pytania:
- Jaka jest kategoria tego błędu: komunikacja, przeoczenie, brak wiedzy, literówka?
- W jaki sposób błąd został wprowadzony?
- W której fazie tworzenia systemu powstał?
- W jaki sposób można zapobiec powstaniu takiego błędu w przyszłości? W jaki sposób podobne błędy mogą być usunięte z innych części systemu (o ile istnieją a nie zostały jeszcze wykryte przez inne techniki)?
Celem spotkania jest uzyskanie sugestii co do zapobiegania poszczególnym błędom. Nie powinno ono utknąć w zbyt szczegółowych rozważaniach (nie może być za długie). Przy końcu spotkania osoba prowadząca powinna zadać następujące pytania:
- Czy w analizowanych błędach widać trend, który może oznaczać szerszy problem?
- Co poszło dobrze podczas poprzedniej fazy? Co przyczyniło się do oszczędzenia czasu?
- Co poszło źle podczas poprzedniej fazy? Co stanowiło największy problem?
- Czy można w jakiś sposób poprawić techniki detekcji błędów, narzędzia, komunikację, edukację w stosunku do stanu aktualnego?
Obecność na takim spotkaniu programistów, którzy pracują nad systemem jest konieczna, ponieważ osoba, która wprowadziła błąd może najlepiej określić przyczynę wprowadzenia błędu.
Wprowadzenie korekt w procesie
Zespół wykonawczy (action team) odpowiada za wprowadzenie w życie akcji prewencyjnych zdefiniowanych w trakcie spotkania. Zespół ten typowo obsługuje wszystkie projekty prowadzone w ramach organizacji. Zwykle każdy członek zespołu odpowiada za jeden segment (definicja procesu, dokumentacja, narzędzia, edukowanie, projekt, programowanie, testowanie).
Oto możliwe rodzaje akcji zapobiegawczych:
- Zmiany w procesie produkcyjnym
- Utworzenie nowych narzędzi
- Szkolenie pracowników (seminaria, techniczne opisy niektórych aspektów produktu, artykuł na temat powtarzających się błędów)
- Zmiany w produkcie (systemie informatycznym), które ułatwiają wykrywanie błędów
- Usprawnienie komunikacji np. automatyczne powiadamianie o zmianach w projekcie dla wszystkich zainteresowanych osób
Mniejsza skala projektów
Opisane w artykule praktyki stosowane są w projektach dużej skali (kilkadziesiąt, kilkaset osób). Naturalnie pojawia się pytanie czy techniki zapobiegania defektom można stosować w projektach mniejszych (kilka, kilkanaście osób) lub w takich, gdzie struktura zespołu jest rozproszona (coraz częściej zdarza się, że zespół jest rozproszony geograficznie).
Według mnie jest to jak najbardziej możliwe. Oczywiście należy dopasować działanie do wielkości i charakteru zespołu:
- Analizę błędów można przeprowadzić przy użyciu kanału e-mail. Jest to mało absorbująca forma kontaktu (nie wymaga obecności w jednym czasie wszystkich członków zespołu)
- Rolę zespołu wykonawczego muszą przejąć członkowie zespołu wraz z automatycznym sprawdzaniem przyjetych reguł w kodzie (analizatory statyczne)
Uważam, że w każdej wielkości projektu korzyści wynikające z zapobiegania defektom są warte poświęconego czasu. Łatwiej jest problem usunąć raz niż wielokrotnie łatać powstałe w jego wyniku skutki na etapie testowania produktu.
Thu, 11 Feb 2010 00:13:07 +0000
J2EE is a set of Java-based technologies used to build applications accessible over the network. Flexibility and the ability to configure, based mainly on XML files, leads to the fact that more and more errors are beyond the control of the compiler.
Older systems described the interaction between parts of the system directly in the code and as such could you checked (at least partially) in the build phase by compiler. The trend to move this kind of information outside of Java code causes, unfortunately, many configuration errors will not be caught by compiler. Those errors will be visible later, at run time.
The complexity of the J2EE architecture makes the cycle (recompilation, installation, testing in a browser) long. This significantly makes the development method "change and run" harder. What can we do to speed up the process of developing J2EE applications?

(This is a translation of an article I wrote two years ago on static verification).
Static Verification
Static verification of software means "correctness proof" for average developer. The aim is to catch errors hidden in the system without actually running it. It should (theoretically) find all implementation bugs before testing phase. However, this idea contains some serious problems:
- In practice, writing a formal specification of functionality is hard (mathematical background required)
- Tools for verification are difficult to use and require a lot of practice for productive use
- It's not possible to automatically checked against a formal specification, human intervention is required
As you can see the complete static verification is not feasible in typical systems. But can we take some benefits from the static verification ideas?
Resources in J2EE
Let's define "resource" term for the purpose of this article. It's an element of a J2EE application that can be analysed independently, and which relates to other resources after installation in the application server. An example of this resource is Java code, analysis is performed by the compiler during compilation. Example of such "resources":
- Java code (no access regular expressions, the mechanism of reflection)
- Struts configuration (no access: the SAX parser)
- JSP files (no access: the SGML parser)
- Setting up Tiles (no access: the SAX parser)
- Translation in ApplicationResources_
- *. properties (the standard Java library)
- ...
Example: Struts static verification
What benefits can be achieved by statically and automatically analysis of above resource? Here are some common errors in J2EE/Struts applications, typically discovered after deployment:
- Exception caused by using a page tag html: text property to the value of an attribute that does not exist as an attribute in the form-bean
- Typo in the action attribute in the tag html: form, which causes confusion in the absence of a URL
- No translation of static text appearing on the tag bean: message
- Improper use of the name attribute in one of the tag causes an runtime exception
Finding such errors, especially when the project is subject to constant scope changes is inefficient and tiring. Wouldn't it be easier to get a complete list of these errors within a few seconds before deployment (instead of wasting time testers such obvious defects)?
I believe that the tester's job is to check compliance with specification, simple errors and typos should no longer appear in testing phase. How can we statically "catch" class of errors described above?
- JUnit test that will match form-bean definitions (POJO classes) with html: text tags and check if properties called from JSP are present in Java class
- Actions called from JSP can be compared to definitions in XML file
- For each instance of the bean: message we can check whether there is an entry in the messages file
- Every "name" used in JSP can be checked against bean list from Struts config file
Implementations
I was able to apply similar techniques for the following software configurations:
- JSF: Java and JSP parsing based on regular expressions, the parser and verifier written in AWK
- Struts: SGML parser for the JSP plus Java reflection API
- Hibernate: static analysis of query parameters in the HQL vs bean class that hold query parameters
Also few implementations from outside Java world:
- Zope ZPT templates: XML parser plus Python reflection API
- Custom regexp-based rules checked against Python code
Summary
Static bug hunting means: early (before runtime) and with high coverage (not available by manual testing). It saves a lot of effort to track simple bugs and leave time for testers to do real work (check against specification).
Sun, 16 May 2010 12:54:46 +0000
Anders Janmyr has written recently an interesting article why he hates static typing:
Donald Knuth wrote in his famous paper Structured Programming with go to Statements (PDF)
We should forget about small efficiencies, say about 97% of the time: pre-mature optimization is the root of all evil
Since compilation is premature optimization, it is therefore, the root of all evil. Simple!
Pretty "smart" reasoning but stupid, IMHO.
He mentioned: "Every time I build my code, my entire code base is type-checked (...) I only care about the method and class that I am currently working on" - yeah, local code change may introduce errors in unexpected parts of a system. I would even use FindBugs if it will improve code quality and slow down total build time. Why? Because I think it's better to allow compiler/lint-tool to control correctness during development process to find most errors as early as possible.
Janmyr assumes the only application of static typing for release preparation (production mode) is better software optimisation. Compiled languages are more efficient than interpreted because many type checks was performed during compile time time and they can be removed from run-time.
I do believe dynamically-typed languages are faster for rapid development (I do love Python, BTW), but there's a hidden cost here. In order to make your code maintainable you have to prepare sufficient level of unit test coverage (I'm using 80% as minumul level for projects in dynamic languages). That's why i'm introducing some kind of static typing by:
I do agree, however, that modern languages are loosing static type-safety by moving configuration outside Java code (XML files, properties, Json) and coding logic in external dynamic sub-languages (JSP). Java gets more type safety from 1.5+ language contructs but most frameworks go in opposite direction.
Isn't Dynamic Typing the Root of All Evil then?

Duck Typing Ducks?
Fri, 27 May 2011 11:06:04 +0000
 When a QT warning is issued you might not know what code is causing activation of this warning. Warnings are not fatal, application is not stopped with proper backtrace. When a QT warning is issued you might not know what code is causing activation of this warning. Warnings are not fatal, application is not stopped with proper backtrace.
QT creators added very useful option for that purpose: QT_FATAL_WARNINGS. If you set:
export QT_FATAL_WARNINGS
You will be correct backtrace under gdb that allow to locate the problem. Application will abort as soon as first QT warning is located.
Fri, 28 Oct 2011 21:25:18 +0000
 Everyone agrees that internal state checking using assert(), Q_ASSERT(), assert are good. Programmer can declare expected input (asserting parameters), internal state (invariants) and verify return values (postconditions) and runtime will verify such expectations. There are languages with direct support for assertions in those three variants (Eiffel with his Design By Contract philosophy). Everyone agrees that internal state checking using assert(), Q_ASSERT(), assert are good. Programmer can declare expected input (asserting parameters), internal state (invariants) and verify return values (postconditions) and runtime will verify such expectations. There are languages with direct support for assertions in those three variants (Eiffel with his Design By Contract philosophy).
Those assertions typically will show filename/line number/message information and abort program / raise an exception if the condition is not met. Runtime environment then can collect current stacktrace to give developer more information on failed expectation.
One can disable assertions entirely (C++, Java) or select subset of assertions (Eiffel) for production releases. Resulting code will be faster, but failed expectations will not be verified by software - problem reports may be harder to interpret.
On the other hand if an assertion is too strict (the assumption may be invalid) it may abort program giving user negative impression about software stability.
What to do then? How can we keep problem-diagnosing power of enabled assertions and prevent minor of invalid failed assertions from aborting whole program?
The answer is: weak assertions (assertion without abort).
OK, you may ask, if we are not calling abort() then we can loose details about failed assertion. Nobody will send a bug report if program is not crashing.
But why do we need to rely on end user? ;-) Let's send failed assertion reports automatically under-the-covers and leave system running!
I'm attaching solution below for Q_ASSERT (C++, QT), but you should get the idea:
void qt_assert_x(const char *where, const char *what, const char *file, int line) {
char buf[BUFSIZE];
snprintf(buf, BUFSIZE, "%s:%d: Q_ASSERT(%s, %s) FAILED", file, line, where, what);
print_stacktrace_to_logs(buf);
send_stacktrace_over_network(buf);
if (getenv("ASSERT_FATAL")) {
abort();
}
}
If you place this code in LD_PRELOAD-ed library you will overload symbol from QT library and catch any reference to qt_assert_x() symbol. Supplied function will save important information into log file, send it using network connection (of possible) then return. I described in this post how can we collect such crash reports on a server and this post will tell you about implementation of stacktraces for C++.
Optionally you can ask for abort() call (typical Q_ASSERT behavior) using some kind of configuration (environment variable in my case). It may be useful in development environment to die early is something goes wrong to have better diagnostics.
Using custom error handlers you can have both benefits:
- "robust" program that will not die after minor expectation is not met (end user will not care)
- automatic diagnostics about failed expectation
Fri, 28 Oct 2011 22:03:27 +0000
I'm tracking current project state using automated test suite that is executed 24/7. It gives information about stability by randomly exploring project state space. Test launches are based on fresh builds from auto-build system connected to master branch for this project.
Recently I hit few times typical stability regression scenario: N+1th commit that should not have unexpected side effects caused crash in auto-testing suite just after 2 minutes of random testing thus blocking full test suite to be executed. OK, we finally had feedback (from auto-test), but let's compute the (bug .. detection) delay here:
- auto-build phase: 30 minutes .. 1 hour (we build few branches in cycle, sometimes build can wait long time to be performed especially if build cache has to be refilled for some reason)
- test queue wait phase: 30 minutes (pending tests should be finished before loading new version)
- review of testing results (currently manual): ~1 hour (we send automatic reports, but only twice a day)
In worst scenario we may notice the problem (regression) next day! Too long time in my opinion - broken master branch state may block other developers thus slowing down their work. There must be better organization that will allow to react faster on such problems:
- Ask developers to launch random test suite locally before every commit. 5 minute automatic test should eliminate obvious crashes from publishing on shared master branch
- Auto-Notify all developers about every failed test: still need to wait for build/test queue, messages may become ignored after long time
- Employ automatic gate keeper-like mechanism that will promote (merge) commit after some sanity tests are passed
Looks like 1. is more efficient and easiest to implement option. 2. is too "spammy" and 3. is hardest to setup (probably in next project with language with ready support for "commit promotion").
- will look interesting if applied to latest submitters only. Maybe I'll give it a try.
Sat, 12 Nov 2011 00:04:05 +0000
 How often do you (I assume a developer) trying to make a suit for this small creature? Aren't such "features" just a mistake in software specification? If it's something that is visible just after product is deployed and it's OK from specification point of view: How often do you (I assume a developer) trying to make a suit for this small creature? Aren't such "features" just a mistake in software specification? If it's something that is visible just after product is deployed and it's OK from specification point of view:
- Someone has not predicted errant situation during specification phase
- OR: your waterfall (yes, it's a linear analysis-project-implementation-test flow!) process is basically not working now
I believe without formal methods you are not able to predict all possible specification inconsistencies before implementation. Even very accurate review process might leave some holes in specification that lead to obvious bugs as a result.
Then usually a customer is forced to:
- accept extra work that needs to be done to remove a bug to be paid separately (so called "change request", usually pretty expensive at the end of a process)
- OR: accept "feature" as is
Why? Because he signed specification! He/she wanted to make fixed-price product so contract must be created. Contract is not perfect, so responsibility for validating it is on contracting side, not the contractor. On the other hand we (the software shop side) like "THE SOFTWARE IS SUPPLIED WITH NO WARRANTY" (note the usual caps) that keeps our responsibility far away.
So: how often your software process introduces such "(cre/fe)atures"?
Sun, 15 Jan 2012 23:09:24 +0000
 Web2Py is a full-stack Python web framework that can be compared to Django, but is easier to learn due to convention-over-explicit-statement preference. In this article I'll check how static verification techniques developed by me for many different environments (JSP, Django templates, TAL, ...) can be applied for web2py environment. Web2Py is a full-stack Python web framework that can be compared to Django, but is easier to learn due to convention-over-explicit-statement preference. In this article I'll check how static verification techniques developed by me for many different environments (JSP, Django templates, TAL, ...) can be applied for web2py environment.
Static verification means locating simple bugs without running application thus very high (>95%) testing coverage (and high related cost) is not required. Instead with trying to cover by tests every possible screen/workflow/code line/... we can scan all codebase and search for some constraints. Most of them (based on my experience) are static - do not depend on runtime data thus can be effectively checked without running an application.
Here's short example of web2py template language:
<a href="{{=URL('books','show')}}">...</a>
As you can see web2py will substitute {{=<python-expression>}}s by evaluated result. In this example URL points to existing module controllers/books.py and function inside this module named 'show'. I assume you see the problem here: one can select undefined module / function and it will result in a runtime error.
First example is purely static: refence (URL('books','show')) will not change during runtime, neither the source code. Then our static checker might be applied succesfully: check if all URL's in all *.html files have proper functions defined in source code.
Technical solution can be composed to the following steps:
- locating all resources to check: scanning given directory in filesystem tree
- locating all interesting fragments in HTML file: I used regexp with arguments to easily extract interesting data
- locating functions in *.py code: because controllers are not plain python modules (expects some data in global namespace) I decided just to scan them textually
Another check that can be done is references inside HTML files (to CSS resources, JS files, ...). This also can be automated:
<script type="text/javascript" src="svgcanvas.min.js"></script>
Source code refactorings might break your links/references and static scan might ensure you are not breaking application by refactoring.
Complete source code for URL() / SRC= / HREF= checker:
import sys
sys.path.append("web2py/applications")
sys.path.append("web2py")
import os
import copy
import re
import string
from gluon.globals import *
from gluon.http import *
from gluon.html import *
RE_SRC = re.compile(r'src *= *"([^"]*)"')
RE_HREF = re.compile(r'href *= *"([^"]*)"')
RE_URL = re.compile(r'{{=URL\(\'([^\']*)\'')
RE_URL2 = re.compile(r'{{=URL\(\'([^\']*)\' *, *\'([^\']*)\'')
FILENAME= None
FNR = 0
request = Request()
def report_error(s):
print "%s:%d: %s" % (FILENAME, FNR, s)
def check_src_exists(arg):
if arg[0] == "{":
# variable value
return
elif arg[0].find("{{"):
# skip this URL
pass
elif arg[0] == "/":
# absolute file
fullPath = "web2py/applications" + "/" + arg
if not os.path.exists(fullPath):
report_error("file %s doesn't exists" % fullPath)
else:
# relative file
fullPath = os.path.dirname(FILENAME) + "/" + arg
if not os.path.exists(fullPath):
report_error("file %s doesn't exists" % fullPath)
def check_href_exists(arg):
#print arg
if arg.startswith("{{="):
pass
elif arg.find("{{") > 0:
pass
elif arg.startswith("/"):
if not os.path.exists("web2py/applications" + arg):
report_error("absolute file %s doesn't exists" % arg)
elif arg.startswith("http://"):
# external link, do not check
pass
elif arg.startswith("https://"):
# external link, do not check
pass
elif arg.startswith("mailto:"):
# external link, do not check
pass
elif arg.startswith("javascript:"):
# external link, do not check
pass
elif arg.find("#") == 0:
# anchor, skip
pass
else:
fullPath = os.path.dirname(FILENAME) + "/" + arg
if not os.path.exists(fullPath):
report_error("relative file %s doesn't exists" % fullPath)
def templatePathToPythonPath(templatePath):
return string.join(templatePath.replace("/views/", "/controllers/").split("/")[:-1], "/") + ".py"
def eq(got, expected):
if got != expected:
print "got:'%s' != expected:'%s'" % (got, expected)
return False
return True
assert eq(templatePathToPythonPath(
"web2py/applications/ad/views/default/details.html"),
"web2py/applications/ad/controllers/default.py")
assert eq(templatePathToPythonPath(
"web2py/applications/ad/views/default/index.html"),
"web2py/applications/ad/controllers/default.py")
assert eq(templatePathToPythonPath(
"web2py/applications/examples/views/ajax_examples/index.html"),
"web2py/applications/examples/controllers/ajax_examples.py")
name_to_contents = {}
def get_file_contents(fileName):
global name_to_contents
if not name_to_contents.has_key(fileName):
if os.path.exists(fileName):
f = file(fileName)
name_to_contents[fileName] = f.read()
f.close()
else:
report_error("Cannot load %s" % fileName)
name_to_contents[fileName] = ""
return name_to_contents[fileName]
def check_url_exists(url):
if FILENAME.find("appadmin.html") > 0:
return
if url.find(".") > 0:
functionName = url.split(".")[-1]
else:
functionName = url
# print "check_url_exists(%s) moduleName=%s" % (url, moduleName)
pythonFilePath = templatePathToPythonPath(FILENAME)
if get_file_contents(pythonFilePath).find("def " + functionName + "()") < 0:
report_error("cannot find %s in %s" % (functionName, pythonFilePath))
def check_url2_exists(moduleName, functionName):
if moduleName == "static":
return
# print "check_url_exists(%s) moduleName=%s" % (url, moduleName)
pythonFilePath = string.join(FILENAME.replace("/views/", "/controllers/").split("/")[:-1], "/") + "/" + moduleName + ".py"
if get_file_contents(pythonFilePath).find("def " + functionName + "()") < 0:
report_error("cannot find %s in %s" % (functionName, pythonFilePath))
def scan_file(path):
global FILENAME
global FNR
FILENAME = path
FNR = 0
f = file(path)
while 1:
FNR += 1
line = f.readline()
if not line:
break
m = RE_SRC.search(line)
if m:
check_src_exists(m.group(1))
m = RE_HREF.search(line)
if m:
check_href_exists(m.group(1))
m = RE_URL2.search(line)
if m:
check_url2_exists(m.group(1), m.group(2))
else:
m = RE_URL.search(line)
if m:
check_url_exists(m.group(1))
f.close()
def test_html(directory):
for a in os.listdir(directory):
if a == "epydoc":
continue
p = directory + "/" + a
if os.path.isdir(p):
test_html(p)
if a.endswith(".html"):
scan_file(p)
test_html("web2py/applications")
Thu, 15 Mar 2012 23:08:25 +0000
A quite typical picture: software development company X, first delivery of project Y to testing team after few months of coding just failed because software is so buggy and crashes so often. Project Manager decides to invest some money in automated testing tool that will solve all stability problems with click-and-replay interface. Demos are very impressive. The tool was integrated and a bunch of tests were "clicked".
After a month we have 10% of tests that are failing. 10% is not a big deal, we can live with it. After additional month 30% of tests fails because important screen design was changed and some tests cannot authorize themselves in application "for some reason". Pressure for next delivery increases, chances to delegate some testers to fix failing test cases are smaller every week.
What are the final results of above tool?
- unmaintained set of tests (and the tool itself) is abandoned
- man-days lost for setting up test cases
- $$ lost for the tool and training
Has the tool been introduced too late? Maybe wrong tool was selected?
In my opinion automation and integration tests don't play well together. Let's review then main enemies of automation in integration tests:
Initial state setup of environment and system itself
For unit-level tests you can easily control local environment by setting up mocks to isolate other parts of system. If you want test integration issues you have to face with integration-level complexity.
No more simple setups! If you want to setup state properly to get expected result you MUST explicitly set state of whole environment. Sometimes it's just impossible or extremely complicated to set it using UI. If you set states improperly (or just accept existing state as a starting point) you will end with random result changes that will make tests useless (depending on the order of tests or just a state left after previous test run).
Result retrieval after operation
OK, we scheduled action A and want to check if record was updated in DB or not. In order to do that some list view is opened and record is located using search. Then record is opened and we can add expectations to that screen. We cross the UI layer two times: one for update operation, second time for result verification. Are we sure the state has been really preserved in database?
Secondly, if we want to check if "e-mail was sent" (an example of external state change): We cannot see that event in application UI. On the other hand catching on SMTP level will be too unreliable and slow (timings). Without mocks it's hard to deliver fast solution there. And mocks usage mean it's not an E2E test, but some kind of semi-integration test.
It will just not work smoothly.
What's next then?
It's easy to criticize everything without proposing (and implementing) efficient alternatives.
So my vision of integration testing:
- I'm not checking results for automated integration testing, it will just doesn't work cannot be maintained efficiently
- I'm usually generating random input to cover as much functionality as possible using high level interfaces (UI)
- I depend on internal assertions/design by contract to catch problems during such random-based testing, they serve as an oracle (the more the results are better)
- More complicated properties could be specified (and tested) by some temporal logic (this technology is not prepared, yet)
Fri, 08 Jun 2012 14:18:53 +0000
Recently I've hit the following exception at FogBugz site (hosted commercial bug tracker which one I'm a happy user):
System.ArgumentException: Invalid syntax: expected identifier, found ')'
Server stack trace:
at FogCreek.FogBugz.Database.CSqlParser.ParseIdentifier(CSqlTokenList tokens)
at FogCreek.FogBugz.Database.CSqlParser.ParseColumn(CSqlTokenList tokens, Nullable`1 fTableNameRequired)
at FogCreek.FogBugz.Database.CSqlParser.ParseTerm(CSqlTokenList tokens, Nullable`1 fInsideSelect,
Nullable`1 fInsideInsert, Nullable`1 fInsideOrderBy)
at FogCreek.FogBugz.Database.CSqlParser.ParseExpression(CSqlTokenList tokens, Nullable`1 fInsideSelect,
Nullable`1 fInsideInsert, Nullable`1 fInsideOrderBy, Nullable`1 fIsBoolean)
at FogCreek.FogBugz.Database.CSqlParser.ParseBoolTerm(CSqlTokenList tokens)
at FogCreek.FogBugz.Database.CSqlParser.ParseBoolExpression(CSqlTokenList tokens)
at FogCreek.FogBugz.Database.CSqlValidator.AssertValid(String s, String sType)
at FogCreek.FogBugz.Database.CSqlValidator.AssertValidWhereList(String s)
at FogCreek.FogBugz.Database.CWhereQuery.AddWhere(String sSqlWhere)
at System.Runtime.Remoting.Messaging.StackBuilderSink._PrivateProcessMessage(IntPtr md, Object[] args,
Object server, Int32 methodPtr, Boolean fExecuteInContext, Object[]& outArgs)
at System.Runtime.Remoting.Messaging.StackBuilderSink.SyncProcessMessage(IMessage msg, Int32 methodPtr,
Boolean fExecuteInContext)
Exception rethrown at [0]:
at System.Runtime.Remoting.Proxies.RealProxy.HandleReturnMessage(IMessage reqMsg, IMessage retMsg)
at System.Runtime.Remoting.Proxies.RealProxy.PrivateInvoke(MessageData& msgData, Int32 type)
at FogCreek.FogBugz.Database.CWhereQuery.AddWhere(String sSqlWhere)
at AlbrektsenInnovasjon.FogBugzData.AddQueryFilter(CWhereQuery query)
at AlbrektsenInnovasjon.FogBugzData.RenderTimesheetReport(StringBuilder page)
at AlbrektsenInnovasjon.FogBugzData.RenderReport(StringBuilder page)
at AlbrektsenInnovasjon.FogBugzTimeSheetReport.FogBugzTimeSheetReportPlugin.FogCreek.FogBugz.
Plugins.Interfaces.IPluginPageDisplay.PageDisplay()
at System.Runtime.Remoting.Messaging.StackBuilderSink._PrivateProcessMessage(IntPtr md,
Object[] args, Object server, Int32 methodPtr, Boolean fExecuteInContext, Object[]& outArgs)
at System.Runtime.Remoting.Messaging.StackBuilderSink.SyncProcessMessage(IMessage msg, Int32 methodPtr,
Boolean fExecuteInContext)
Exception rethrown at [1]:
at System.Runtime.Remoting.Proxies.RealProxy.HandleReturnMessage(IMessage reqMsg, IMessage retMsg)
at System.Runtime.Remoting.Proxies.RealProxy.PrivateInvoke(MessageData& msgData, Int32 type)
at FogCreek.FogBugz.Plugins.Interfaces.IPluginPageDisplay.PageDisplay()
at FogCreek.FogBugz.__Global.PluginPage(Int32 ixPlugin) in c:\code\hosted\build\FB\8.8.28H\fogbugz\
src-Website\pluginPages.was:line 35
at FogCreek.FogBugz.__Global.RawpgPlugin() in c:\code\hosted\build\FB\8.8.28H\fogbugz\src-Website\
default.was:line 3753
at FogCreek.FogBugz.__Global.pgPlugin() in c:\Users\john\AppData\Local\Temp\dxcwqgiu.0.cs:line 0
at FogCreek.FogBugz.__Global.RunPg() in c:\Users\john\AppData\Local\Temp\dxcwqgiu.0.cs:line 0
at Wasabi.Runtime.Web.Response.PictureOf(Sub sub) in c:\code\hosted\build\FB\8.8.28H\wasabi\
Wasabi.Runtime\ResponseGenerator.cs:line 24
at FogCreek.FogBugz.__Global.RawRunFogBugz() in c:\code\hosted\build\FB\8.8.28H\fogbugz\
src-Website\default.was:line 4661
at FogCreek.FogBugz.__Global.RunFogBugz() in c:\Users\john\AppData\Local\Temp\dxcwqgiu.0.cs:line 0
at FogCreek.FogBugz.__Global.StartDefault() in c:\code\hosted\build\FB\8.8.28H\fogbugz\
src-Website\default.was:line 131
at FogCreek.FogBugz.HttpHandler.ProcessRequest(HttpContext context) in c:\Users\john\
AppData\Local\Temp\dxcwqgiu.0.cs:line 0
The fact that stacktrace is visible on public site (it may espose many internal details of implementation) is one major problem with that site, the information you can gather: a challenge. Let's investigate then.
Besides the stacktrace alone I have access to all components versions used (not included here of course). That's bad. You can exploit potentially not patched components vulnerabilities based on that information to potentially gain unauthorised system access.
From this info:
An internal error occurred in FogBugz. This error has already been reported to Fog Creek Software. We do not respond personally to every error submission. If you would like an immediate response to this issue please contact us through our website at https://shop.fogcreek.com/mail.
I see that such crash reports are automatically collected on FogCreek Software side. That's good. You have to collect such data and process it carefully to find and eliminate runtime problems in a future.
Findings:
- FogCreek.FogBugz.Database.CWhereQuery: it seems FC guys use home made ORM to communicate with SQL backend: good/bad? Not sure, tried both (home made, standard) solutions, both have advantages/disadvantages
- System.Runtime.Remoting.Messaging.StackBuilderSink.SyncProcessMessage: looks like front-end back-end are separated (different servers?)
- AlbrektsenInnovasjon.FogBugzData.AddQueryFilter: a confirmation who wrote/is writing the timeshit report
- c:\Users\john\AppData\Local\Temp\dxcwqgiu.0.cs: John is an administrator here
- FogCreek.FogBugz.Database.CWhereQuery.AddWhere on client-side: it seems to collect full parameter list you have to do many remote calls (instead of one call with some complex data structure composed at client side) - a possible deficiency
- Wasabi.Runtime: it seems it's Joel's own compiler
- AlbrektsenInnovasjon.FogBugzData.AddQueryFilter(): this method converts StringBuilder (probably URL parameters) into CWhereQuery and probably the error is hidden here
What was wrong here? Probably not enough unit test coverage for AlbrektsenInnovasjon.FogBugzData.AddQueryFilter() method that is obviously not working for complex report queries. That's why I think production reporting is so valuable - you can get samples not found during normal testing. I hope this input I've just generated will be used by developers.
Fri, 11 Oct 2013 21:06:43 +0000
By searching for already existing implementations of random input-based testing attempts I've located the following material that describes possible level of implementation of that idea using web browser code tests:
Udacity splits possible implementation into the following levels, I've added interpretation in case if there's no browser alone under test, but the server side application:
- verifying only HTTP protocol - HTTP errors 500, 404 will be handled on that level
- HTML level checks - any problems with tags nesting, SGML/XML syntax can be caught there
- rendering - can check any layout-related issue (overlapping divs)
- forms and scripting - checks application logic using client-side language and local state (forms and cookies)
By testing on any of above levels you select application coverage vs level coverage. My idea is to connect random input on all above input levels with validation of every level contracts plus internal contracts check on server. Then we will have the following output:
- caught any HTTP, HTML, rendering (I know it might be hard to automate) and state-related error (not easy to define error here, though)
- collect any assertion, warning, error, crash etc. from server side application with full stacktraces and aggregation
Sun, 22 Dec 2013 13:03:47 +0000
Automated unit tests are hard to write. Software architecture must be designed carefully to allow unit testing. You have to spend time to write tests as well and it's not easy to write good tests. It's easy to make big mess that is hard to maintain after few weeks.
On the other hand automated integration tests are hard to maintain and are fragile. You can "write" them pretty easy in a record-and-replay tool, but later they show their real cost during maintenance.

But there's an answer for problems mentioned above. Do you know Eiffel language? The language has special built-in constructs that support executable contract specification. It's called Design By Contract (DBC). DBC is easier to write and to maintain because no special test cases need to be specified, just conditions for method parameters, expected results and state invariant that must be preserved. How DBC can substitute old-fashioned tests? Read on!
General concepts for DBC are:
- pre-condition: you can specify rules for every input parameter to check contract fulfillment from caller side. If a pre-condition is not met that means there's something wrong with caller
- post-condition: rules for post-method execution state can be specified as well. You can refer to input parameters, current object state and original object state (before method call)
- class invariants: refers to object members and must be valid after every public class call
As an example I'll use DBC implementation called "pycontract" (Python language). It's pretty easy to introduce in a project and uses standard doc-strings (like doctest module). No preprocessing is needed.
Pre-condition is specified by pre keyword:
pre:
someObject != None and someObject.property > 0
Post-condition syntax uses some special syntax to allow to refer to old values, you have to mention mutable variables object that should be available for state change comparisions:
post[self]:
self.property = __old__.self.property + 1
Above statement shows that property should be incremented by one after method return.
Invariant syntax is as follows:
inv:
self.state in [OPEN, CLOSED, SENT]
All above statements must be embedded in method/class comments, here's full example:
class SampleClass:
"""
inv:
self.state in [OPEN, CLOSED, SENT]
"""
def open(self, x):
"""
pre: x > 0
post: self.state != CLOSED
"""
DBC assertions (like doc-strings) are disabled by default (they are just comments). You can decide to enable them for example in development builds (there's an overhead related to DBC). An example how to enable pycontract:
import contract
contract.checkmod(modulename1)
contract.checkmod(modulename2)
Example failure (postcondition not met) caught by DBC:
DokumentFiskalny.testDokumentu() Traceback (most recent call last):
File "test.py", line 164, in
run_tests()
File "test.py", line 144, in run_tests
run_test_module(db, dao, moduleName)
File "test.py", line 54, in run_test_module
exec("%s.%s(env)" % (sName, sItem))
File "", line 1, in
File "", line 3, in __assert_testDokumentu_chk
File "lib/contract.py", line 1064, in call_public_function_all
return _call_all([func], func, va, ka)
File "lib/contract.py", line 1233, in _call_all
result = func.__assert_orig(*va, **ka)
File "/home/darek/public_html/kffirma/DokumentFiskalny.py", line 433, in testDokumentu
df.zapisz(args)
File "/home/darek/public_html/kffirma/DokumentFiskalny.py", line 254, in zapisz
args["idPodmiotuGospodarczego"],
File "", line 3, in __assert_DokumentFiskalny__create_chk
File "lib/contract.py", line 1165, in call_private_method_all
return _method_call_all(getmro(cls), method, va, ka)
File "lib/contract.py", line 1205, in _method_call_all
return _call_all(a, func, va, ka)
File "lib/contract.py", line 1241, in _call_all
p(old, result, *va, **ka)
File "", line 3, in __assert_DokumentFiskalny__create_post
File "/home/darek/public_html/kffirma/DokumentFiskalny.py", line 155, in _create_post
assert len(result) >= 2
The last part of this puzzle is coverage generation. DBC assertions are evaluated at runtime, so you have to ensure enough percentage code is execute during test runs. Im my experience you can rely on:
- integration-like scenarios (without explicit result verification)
- random input generation
For both cases you can integrate at high, UI level (keyboard, remote controller, HTTP, ...).
Focus on quality techniques is crucial for any software project. If you (1) pay some effort in making your codebase resistant to regressions and (2) maintain that state during project lifetime you can gain more stable software. The real craft lies in selecting proper tools and having enough energy to implement them.
Sun, 10 Jan 2016 00:34:02 +0000
 Executable specification is a "holly graal" of modern software engineering. It's very hard to implement as it requires: Executable specification is a "holly graal" of modern software engineering. It's very hard to implement as it requires:
- Formal specification of rules
- Transformation of those rules into real-system predicates
- Stimulating system under tests state changes in repeatable manner
FitNesse is one of such approaches that specifies function sample inputs and outputs then allow to run such test cases using special connectors and provide colour reports from test runs. It's easy to use (from specification point of view), but has the following drawbacks:
- Software architecture must be compatible with unit testing (what is very good in general: cut unnecessary dependencies, Inverse of Control, ...) - your current system might require heavy refactoring to reach such state
- Rules are written and evaluated only during single test execution - different scenario requires another test case (no Design By Contract style continuous state validation)
Above features are present in any other unit test framework: JUnit, unittest, ... All such testing changes state and checks output.
And now quite crazy idea has come to my mind:
What if we forget about changing state and focus only on state validation?
 Then the executable specification won't be responsible for "test driver" job. Only state validation would be needed (including some temporal logic to express time constraints). That is much easier task to accomplish. Then the executable specification won't be responsible for "test driver" job. Only state validation would be needed (including some temporal logic to express time constraints). That is much easier task to accomplish.
What about state changing then (the "Test Driver" role in the diagram) - you might ask? We have two options here:
- random state changes to simulate global state machine coverage (randomtest.net)
- click'n'play tools (which I hate, BTW) to deliver coverage over some defined paths (Selenium)
- some API-level access to change system state and execute some interesting scenarios (system-dependant)
So let's go back to Specification then. Let's review some high level requirements (taken randomly from IPTV area) written in English and how they could be transformed into formal specification languages (I'm borrowing idea of "test tables" from FitNesse):
A requirement: video should be visible after device boot unless it's in "factory reset" state
Here we have the following state variables:
- 1st_video_frame = true: detected by checking for special strings in decoder logs
- device_boot = true: one could find unique entry in kernel log that shows device boot
- factory_reset = true: missing some local databases state
Once parameters meaning has been specified by existence of log entries we could write the decision table here:
| device_boot | factory_reset | 1st_video_frame? | timeout |
| true | false | true | 120s |
| true | true | false | 120s |
As you might have noticed I've added extra parameter "timeout" that delivers the temporal part of the constraint. The meaning of this parameter is as follows:
Given input condition is set the output condition should be met (even temporarily) in the timeout period
A requirement: the device should check for new software versions during boot or after TR-69 trigger, user might decide about the upgrade in both cases
Here we define the following state variables:
- device_boot = true: the first kernel entry
- check_software = true: proper log entry related to network activity for new software version retrieval
- tr69_upgrade_trigger = true: local TR69 agent logs
- user_upgrade_dialog = true: upgrade decision dialog visible
The decision table:
| device_boot | tr69_upgrade_trigger | check_software? | user_upgrade_dialog? | timeout |
| true | - | true | - | 160s |
| - | true | true | - | 30s |
(I use "-" as "doesn't matter" marker)
And here comes the hard part: we don't know whether new software is present for installation, so we cannot decide about user dialog. New property is needed:
And the table looks like this:
| device_boot | tr69_upgrade_trigger | new_sf_version_available | check_software? | user_upgrade_dialog? | timeout |
| true | - | true | true | true | 160s |
| - | true | true | true | true | 30s |
| true | - | true | false | false | 160s |
| - | true | true | false | false | 30s |
We can see that table behaviour is a bit redundant there: we needed to multiply specification entries to show (tr69_upgrade_trigger x new_sf_version_available) cases.
However, above test will show failures when:
- Despite the new version presence there was no software update dialog visible
- No new version check has been triggered 160s after boot
- ...
A requirement: rapid channel change should not exceed 600ms
This one looks a bit harder because of the low timeout and the usual buffering done on logs. However, having log flush interval limited to 100ms one can keep quite good performance and measure time with enough granularity.
Another caveat here is to exclude channels that are not available in current provisioning of the customer (you should see some up-sell page instead).
The states variable definition:
- 1st_video_frame: specification as above
- channel_up: P+ key has been pressed
- channel_down: P- key has been pressed
- channel_unavailable: system detects that current channel/event is not purchased yet
The specification:
| channel_up | channel_down | channel_unavailable | 1st_video_frame? | timeout |
| true | - | false | true | 800ms |
| - | true | false | true | 800ms |
Note that channel availability detection must be done at the same moment as channel change event - might be not true in most implementations (so not possible to reflect in our simple temporal logic language).
The implementation feasibility
In order above method to work it requires some kind of implementation.
- System state changes detection: the output of a system could be serialized in single stream of textual events (redirected to serial line for embedded device, application server logs on server-based system)
- Each interesting state variable changes could be derived from regexp parsing of above stream
- On each state change all the collected rules would be examined to find active ones
- The rules with timeout would setup a timeout callback to check the expected output state changes
The outputs of such test:
- Failed scenarios with timestamp - for further investigation
- Rules coverage - will tell you how good (or bad) your test driver is (how much coverage is delivered)
Based on first output you need to adjust your rules / matching patterns. Based on the second you should adjust your test driver policy.
It look like a feasible idea for implementation. I'm going to deliver a proof of concept in randomtest.net project.
2016-02-04
Joint Test Action Group (JTAG) is a IEEE Standard Test Access Port and Boundary-Scan Architecture. It describes communication standard used mainly for embedded devices for:
- debugging - reading internal system state in runtime
- firmware upgrades - re-programming of internal software
- boundary scan testing - alter internal interfaces directly to simulate system state that is hard to reproduce in normal scenarios
JTAG requires some additional connections to be present on board:
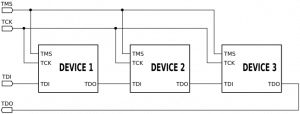
Is there a method we could use above ideas to improve higher level (let's say J2EE-based system) development? Read on!
Debugging
Debugging activities typically depend on external debugger that is attached to the running process. Using such approach you have detailed insight into running system with all important state exposed. However such approach is not always possible (checking production deployment for example.
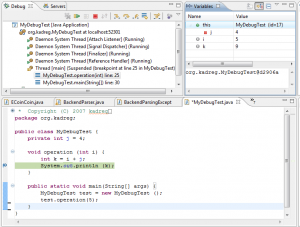
If "thick" debugger is not available there's a poor man's alternative: application logs. Almost every modern logging library has the ability to switch logging level and enable / disable certain log categories. This way you can have detailed view of selected component (assuming you have added the logs to application in advance).

|
Tags
|









