About This Site
Software development stuff
Archive
- 2017
- 2016
- 2015
- 2014
- 2013
- 2012
- 2011
- 2010
- 2009
- 2008
- 2007
|
Entries tagged "build".
Sat, 06 Feb 2010 14:12:46 +0000
 During software development (especially done in agile way) there are often time when working software release must be prepared for customer evaluation of internal testing. I found many software release managers use a feature called "commit freeze": no one can commit to main branch of development (trunk/master) until release is packaged. I doubt if it is really required. During software development (especially done in agile way) there are often time when working software release must be prepared for customer evaluation of internal testing. I found many software release managers use a feature called "commit freeze": no one can commit to main branch of development (trunk/master) until release is packaged. I doubt if it is really required.
The possible reason for freezing commits:
Creating releases
If you want to make minor changes related to release and block any other (probably more risky) changes to be accidentially introduced you needn't freeze commits. The more efficient solution here is to fork a branch. On separate branch you can do any justification you need to build the binaries for release.
Merging
For time-consuming merges (especially when many conflicts are present) it's tempting to prevent commits on target branch to minimize problems related to local development during merged changes commit. I think merging person should perform frequent updates insted from current branch and match merged changes to current trunk state.
Switch version control software / repositories
Switching between version control system is a big change in development team. One has to learn new toolset to operate efficiently with new version control system. Postponing commits on old repository is not required. Those changes could be reapplied later by creating patch from missing changesets and applying them on new repository. Patch format is a standard that allow to move changesets beteen different repositories.
Summary
In my opinion temporary blocking commits (so called "commit freeze") is not a good idea. Agile methodology (the one we use at Aplikacja.info) requires frequent information sharing. There are alternatives that have lower impact on development and not get in the way for normal code flow.
Tue, 02 Mar 2010 13:44:12 +0000
 Creating software projects is composed of many activities. One of them (not very appreciated by typical developer) is building process. The activity should create executables or libraries from source code. You may say now: hey, you forget about documentation, generated API specification, installation, deployment, ...! As you can see there are many task realised by this activity. Creating software projects is composed of many activities. One of them (not very appreciated by typical developer) is building process. The activity should create executables or libraries from source code. You may say now: hey, you forget about documentation, generated API specification, installation, deployment, ...! As you can see there are many task realised by this activity.
I'll review most popular building tools and will point out their strengths and weaknesses:
- Make
- Ant
- Maven
- IDE-based builders
Make
Make is the oldest tool mentioned here. Comes from UNIX world, is very popular among all non-java projects. Make uses "Makefile" text file with build specification. Here is sample Makefile that builds executable from C source code:
helloworld: helloworld.o
cc -o $@ $<
helloworld.o: helloworld.c
cc -c -o $@ $<
clean:
rm -f helloworld helloworld.o
General makefile syntax:
target: dependicies
<tab>command1
<tab>command2
...
You can chain dependencies and make will resolve them properly and build them in correct order.
Make is used for Linux kernel development and (with configure, imake, ... support) for many Unix based programs.
Make main benefits:
- compact syntax
- basic functionality is a standard among all implementations
- very popular among operating system distributions
Main disadvantages:
- Sometimes <tab> usage requirement may be hard for novices
- Syntax may be cryptic for beginners
Ant
Few quirks built into Make tool (TAB requirement for instance, portability problems, etc) caused Ant to be born. It's Java-based, XML-driven tool that is used mainly for building Java based projects.
<?xml version="1.0"?>
<project name="Hello" default="compile">
<target name="clean" description="remove intermediate files">
<delete dir="classes"/>
</target>
<target name="clobber" depends="clean" description="remove all artifact files">
<delete file="hello.jar"/>
</target>
<target name="compile" description="compile the Java source code to class files">
<mkdir dir="classes"/>
<javac srcdir="." destdir="classes"/>
</target>
<target name="jar" depends="compile" description="create a Jar file for the application">
<jar destfile="hello.jar">
<fileset dir="classes" includes="**/*.class"/>
<manifest>
<attribute name="Main-Class" value="HelloProgram"/>
</manifest>
</jar>
</target>
</project>
Ant tries to extend portability by supplying many built-in operations (make uses shell commands here).
Ant is still low-level tool. You can compose your build process any way you want (you can customize almost everything). The need for creating higher level of abstraction created next tool.
Maven
Maven uses "convention over configuration" philosophy. Configuration is also written in XML, but, unlike Ant, you tell Maven the "WHAT", not "HOW". Most parameters (source folders, target folders) have sensible defaults and you can (theoretically) start work on any Maven based project without surprises.
Main Maven benefits:
- standardised project structure
- binary libraries are stored outside source tree (you declare dependencies, libraries are downloaded on demand during build)
- support for multi-project builds with complicated dependencies
The main problem you can face is the distance from low-level build commands to user interface. Some details are not visible and you need big experience with Maven to diagnose properly problems that may occur during a build.
IDE-based builders
Very popular option for novice/Windows programmers. You can setup build configuration within your IDE (Integrated development Environment) and expect all executables/libraries be build.
Benefits:
- Easy to use
- Incremental builds
Drawbacks:
- Hard to connect to continuous integration tools
Every big project I was working on had IDE-based build duplicated with Maven/Ant based scripts. Why? Because Hudson/Cruise Control builds were created using scripting interface. You can use IDE builders as help during development (it's faster than script rebuilds).
What to choose?
It depends:
- Small project created on Unix machine: use Make
- Bigger project with custom build commands: use Ant
- Multi project build with complicated dependencies: use Maven
Good luck :-)
Sat, 16 Oct 2010 14:28:02 +0000
 Last week I've been observing details of integrating source code coming from three different development teams (located in different countries). Each team owns some subset of modules and has R/W access only to those modules. Of course compile dependencies cross the borders in many places, so global changes usually done in one commit had to be split into at least two commits (because of missing W permission for someone). Last week I've been observing details of integrating source code coming from three different development teams (located in different countries). Each team owns some subset of modules and has R/W access only to those modules. Of course compile dependencies cross the borders in many places, so global changes usually done in one commit had to be split into at least two commits (because of missing W permission for someone).
There was one development branch and one integration branch. Development branch most of this time was in not "buildable" state (permanent build error), so no one was able to ensure changes are not breaking the build before commit until stabilisation. Integration branch was loaded using files copied from development branch when stable state was achieved (I know, lame). This integration style (allowing for non-buildable commits on development branch) blocks parallel integrations (one have to wait for stable state on development branch).
Are there better ways to organise such integration?
Shared Codebase Ownership
In this scenario every team has full write access to all modules and it's possible to create single commit by team T1 that spans module boundaries: refactors module A (owned by T2) AND calling code from module B (owned by T1).
There will be only one "a must" rule: all codebase should be compilable after every commit. Modifications to "not owned" modules should be minimised (only to make code compilable), probably with some "FIXME" left in code.
Doing that operations in single commit allows you (1) to inspect that commit afterwards (2) retain "green build" property after every commit.
Having always-compilable head we will be able to schedule such operations in paralell. Nobody will be blocked (of course teams have to communicate/consult such cross-border changes before commit).
In this case applied changes are visible by diff-ing selected changesets.
Topic Branches
If globally shared codebase is not an idea to be considered we could use short-living branches (called sometimes "topic branches") that get updates from both teams and after stabilisation they are merged back into main branch (and deleted).
Code on topic branch could be unstable, on development branch must be always stable.
Note that merging person should have write access to all "dev" branch (in this aspect this strategy is similar to previous one). I used to place at this point code review process.
In this case pending changes are visible by doing a diff on existing topic branch.
Moving "Stable" Tag
This strategy can be used for file-tracking systems like CVS or Perforce. For those VCS-es one can move tag to new version for subset of files (SVN, GIT, Bazaar will not allow that).
Person that created "stable" commit should create/move some tag to current revision.
$ p4 tag -l STABLE ...
Then anyone interested in stable state would sync to that state:
$ p4 sync ...@STABLE
Then I can fetch fresh (from head) files I'm going to change:
$ p4 sync P1/...
After adding fixes I'm committing the change:
$ p4 submit
and moving stable label for files I've changed (I must check if full build is green before):
$ p4 tag -l STABLE P1/...
In this case pending changes are visible by diff-ing STABLE..head revisions range.
Summary
If some independent activities cannot be performed in paralell it's a bad sign. It means some artificial dependencies were introduced and it results in slower progress for project (caused by serialisation).
In this case missing "W" access was the cause for additional burden. Unstable main branch was a global semaphore that blocked everyone (at least in integration terms).
Mon, 21 Mar 2011 23:30:08 +0000
C++ compiler is pretty big and slow tool and if one needs to make full rebuilds very often waiting for build finish is very frustrating. For those guys "ccache" tool was created.
How is it working? Compiler output (*.o files) are cached under key that is computed from preprocessed source code, compiler versions, build switches. This way builds might be much faster.
Qmake is a Makefile generator that comes with QT and allows for easy build of QT-based (and other) projects. In order to join ccache and qmake one have to update so called "mkspecs" files. How to do that?
It's easy using sed (I'm including only sh4 and mipsel crosscompiler toolchains):
# sed -i '/QMAKE_CXX .*= *[^c][^c]/s/= /= ccache /' \
`find /usr/local -name qmake.conf | grep 'linux-\(sh4\|mipsel\)'`
And how to revert:
# sed -i '/ccache/s/ccache / /' \
`find /usr/local -name qmake.conf | grep 'linux-\(sh4\|mipsel\)'`
Of course you can manually launch an editor and update those files, but a bit of sed scripting is many times faster ;-)
Sat, 11 Feb 2012 01:07:39 +0000
 When you hit some level of code size in a project you starting to observe the following sequence: When you hit some level of code size in a project you starting to observe the following sequence:
- Developer creates and tests a feature
- Before submitting commit to repository update/fetch/sync is done
- Developer builds project again to check if build/basic functionality is not broken
- Smoke tests
- Submit
During step 3 you hear "damn slow rebuild!". One discovers that synchronization with repository forces him to rebuild 20% of files in a project (and it takes time when project is really huge). Why?
The answer here is: header dependencies. Some header files are included (directly and indirectly) in many source code files, that's rebuild of so many files is needed. You have the following options:
- Skip build dependencies and pray resulting build is stable / working at all
- Reduce header dependencies
I'll explain second option.
The first thing to do is to locate problematic headers. Here's a script that will find most problematic headers:
#!/bin/sh
awk -v F=$1 '
/^# *include/ {
a=$0; sub(/[^<"]*[<"]/, "", a); sub(/[>"].*/, "", a); uses[a]++;
f=FILENAME; sub(/.*\//, "", f); incl[a]=incl[a] f " ";
}
function compute_includes(f, located,
arr, n, i, sum) {
# print "compute_includes(" f ")"
if (f ~ /\.c/) {
if (f in located) {
return 0
}
else {
located[f] = 1
return 1
}
}
if (!(f in incl)) {
return 0
}
# print f "->" incl[f]
n = split(incl[f], arr)
sum = 0
for (i=1; i<=n; i++) {
if (f != arr[i]) {
sum += compute_includes(arr[i], located)
}
}
return sum
}
END {
for (a in incl) {
n = compute_includes(a, located)
if (F) {
if (F in located && a !~ /^Q/) {
print n, a
}
}
else {
if (n && a !~ /^Q/) {
print n, a
}
}
for (b in located) {
delete located[b]
}
};
}
' `find . -name \*.cpp -o -name \*.h -o -name \*.c` \
| sort -n
Sample output:
266 HiddenChannelsDefinitions.h
266 nmc-hal/hallogger.h
268 favoriteitemdefinitions.h
270 nmc-hal/playback.h
279 pvrsettingsitemdefinitions.h
279 subscriberinfoquerier.h
280 isubscriberinfoquerier.h
286 notset.h
292 asserts.h
As you can see there are header files that require ~300 source files to be rebuilt after change. You can start optimisations with those files.
If you locate headers to start with you can use the following techniques:
- Use forwad declaration (class XYZ;) instead of header inclusion (#include "XYZ.h") when possible
- Split large header files into smaller ones, rearrange includes
- Use PIMPL to split interfaces from implementations
Wed, 08 Aug 2012 09:52:34 +0000
Recently I've hit problem that some package was silently not installed in rootfs. The reason was visible only in debug mode:
$ bitbake -D
(...)
Collected errors:
* opkg_install_cmd: Cannot install package libnexus.
* opkg_install_cmd: Cannot install package libnexus-dbg.
* resolve_conffiles: Existing conffile /home/sdk/master/wow.mach/tmp/rootfs/sdk-image/etc/default/dropbear
is different from the conffile in the new package. The new conffile will be placed
at /home/sdk/master/wow.mach/tmp/rootfs/sdk-image/etc/default/dropbear-opkg.
* opkg_install_cmd: Cannot install package libpng.
* opkg_install_cmd: Cannot install package libpng-dbg.
* opkg_install_cmd: Cannot install package directfb.
* opkg_install_cmd: Cannot install package directfb-dbg.
* opkg_install_cmd: Cannot install package libuuid-dbg.
* check_data_file_clashes: Package comp-hal wants to install file /home/sdk/master/wow.mach/tmp/rootfs/sdk-image/etc/hosts But that file is already provided by package * netbase-dcc
* opkg_install_cmd: Cannot install package package1.
/etc/hosts file was clashes with one from netbase-dcc package. The solution was to re-arrange file list for comp-hal (not include /etc/hosts there):
FILES_${PN} = "\
(...)
/etc \
/usr/local/lib/cecd/plugins/*.so* \
/usr/local/lib/qtopia/plugins/*.so* \
(...)
/etc specification was replaced by more detailed description:
FILES_${PN} = "\
(...)
/etc/init.d \ /etc/rc3.d \
/usr/local/lib/cecd/plugins/*.so* \
/usr/local/lib/qtopia/plugins/*.so* \
(...)
Thu, 09 Aug 2012 12:14:08 +0000
OpenEmbedded is a framework for building (linux based) distributions. It's something like "Gentoo for embedded systems".
Ccache is a tool that allows to reuse building results thus gives big speed improvements for frequent rebuilds (>10x faster or more then full rebuild).
For the current project I was given responsiblity for existing build system reorganisation. We have many hardware targets and sometimes full rebuild of whole operating system can take many hours even on strong machine (16 cores in our case).
Of course you can reuse existing build artefacts (*.o files), but sometimes it can be dangerous (we cannot gurantee header dependencies are properly tracked between projects). Thus "whole rebuild" sometimes is necessary.
I need every build will be created using ccache: native (for x86) and for target platform (sh4, mipsel). Ccache allows "integration by symlink": you create symlink from /usr/bin/ccache to /usr/local/bin/cc and ccache will discover compiler binary on PATH (/usr/bin/cc) and call it if necessary (rebuild of given artifact is needed). I used that method of ccache integration.
On the other hand OpenEmbedded allows to insert arbitrary commands before every build using so called "bbclasses" and "*_prepend" methods. Below you will find integration methid applied to very basic OE base class: base.bbclass, thus ensuring every build will use ccache:
openembedded/classes/base.bbclass:
(...)
do_compile_prepend() {
rm -rf ${WORKDIR}/bin
ln -sf `which ccache` ${WORKDIR}/bin/`echo ${CC} | awk '{print $1}'`
ln -sf `which ccache` ${WORKDIR}/bin/`echo ${CXX} | awk '{print $1}'`
export PATH=${WORKDIR}/bin:$PATH
export CCACHE_BASEDIR="`pwd`"
export CCACHE_LOGFILE=/tmp/ccache.log
export CCACHE_SLOPPINESS="file_macro,include_file_mtime,time_macros"
export CCACHE_COMPILERCHECK="none"
}
As a result you will receive pretty good hit rate during frequent rebuilds:
$ ccache -s
cache directory /home/sdk/.ccache
cache hit (direct) 50239
cache hit (preprocessed) 27
cache miss 889
called for link 3965
no input file 33506
files in cache 182673
cache size 9.6 Gbytes
max cache size 20.0 Gbytes
Fri, 19 Apr 2013 08:26:10 +0000
Openembedded is a tool to build Linux-based distribudions from source where you can customize almost every aspect of operating system and it's default components. Used mainly for embedded systems development. I'll show today how you can check easily (command-line, of course) dependencies chain.
Sometimes you want to see why particular package has been included into the image.
$ bitbake -g devel-image
NOTE: Handling BitBake files: \ (1205/1205) [100 %]
Parsing of 1205 .bb files complete (1130 cached, 75 parsed). 1548 targets, 13 skipped, 0 masked, 0 errors.
NOTE: Resolving any missing task queue dependencies
NOTE: preferred version 1.0.0a of openssl-native not available (for item openssl-native)
NOTE: Preparing runqueue
PN dependencies saved to 'pn-depends.dot'
Package dependencies saved to 'package-depends.dot'
Task dependencies saved to 'task-depends.dot'
By using:
grep package-name pn-depends.dot
you can track what is the dependency chain for particular package, for example, let's see what's the reason for inclusion of readline in resulting filesystem:
$ grep '>.*readline' pn-depends.dot
"gdb" -> "readline"
"python-native" -> "readline-native"
"sqlite3-native" -> "readline-native"
"sqlite3" -> "readline"
"readline" -> "readline" [style=dashed]
$ grep '>.*sqlite3' pn-depends.dot
"python-native" -> "sqlite3-native"
"qt4-embedded" -> "sqlite3"
"utc-devel-image" -> "sqlite3"
"sqlite3" -> "sqlite3" [style=dashed]
"devel-image" -> "sqlite3" [style=dashed]
"devel-image" -> "sqlite3-dbg" [style=dashed]
As we can see that it's the "devel-image" that requested "sqlite3" and then "readline" was incorporated as a dependency.
*.dot fomat can be visualised, but it's useles feature as the resulting graph may be too big to analyse.
Sat, 03 Jan 2015 17:46:10 +0000
 If you are an embedded software developer like me chances are you use embedded Linux for the purpose. It's Open Source, has great tools support and is a great software environment where (almost) everything could be automated through command line interfaces. If you are an embedded software developer like me chances are you use embedded Linux for the purpose. It's Open Source, has great tools support and is a great software environment where (almost) everything could be automated through command line interfaces.
Once you decide about operating system used the next step is to choose a build system that would be used for the task of building the software. There are few choices you can select from:
- use pre-built toolchain and rootfs and add your binaries and configuration files (i.e. STLinux for ST-based devices)
- use OpenEmbedded for full-featured buildsystem with packaging system included
- use BuildRoot for simple build system without packaging system included
Today I'm going to tell you about the 3rd option. Buildroot states their view on packaging systems for embedded development this way:
We believe that for most embedded Linux systems, binary packages are not necessary, and potentially harmful. When binary packages are used, it means that the system can be partially upgraded, which creates an enormous number of possible combinations of package versions that should be tested before doing the upgrade on the embedded device. On the other hand, by doing complete system upgrades by upgrading the entire root filesystem image at once, the image deployed to the embedded system is guaranteed to really be the one that has been tested and validated.
After few years with OpenEmbedded and few months with Buildroot I like the simplicity of Buildroot model. Below you can find basic (the most important in my opinion) concepts of Buildroot.
Buildroot uses basic "make" interface and, actually, it's written in Makefile language. It's clearly visible in (sometimes) weird syntax for packages declaration. For configuration Config.in files are used (the same as for Linux kernel configuration). It's quite useful and extensible choice for configuration and building.
Recipes system (usually placed under package/ subdirectory) describes in Makefile+Config.in language rules for fetching / configuring / building / installing. You can build+install selected package by issuing: "make <pkg-name>" - quite simple and elegant solution.
Each build is configured in .config file that could be edited make well-known "make menuconfig" interface:
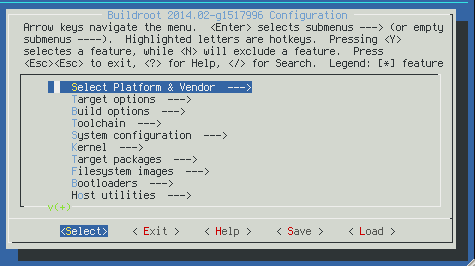
You could select build switches there as well as list of included packages.
All the output is placed under "output" subdirectory (you can force full clean by deleting this directory):
- build/<pkg-name>/ - working directory for building given package (no "rm_work" there as in OE, build directories are kept after build)
- build/<pkg-name>/.stamp_* - describes build state for given package, you can force given stage by deleting selected files there
- host/ - the toolchain
- target/ - rootfs (filled in fakeroot mode) used for creating resulting images
- images/ - resulting images are placed there (tgz, squashfs, kernel binary and so on)
Basic input directories:
- package/<pkg-name>/<pkg-name>.mk - a recipe for given package (Makefile syntax)
- Config.in - root of configuration files possible options
- dl/ - this directory is not stored in version control system, but holds cached version of downloads. It's placed outside of output directory in order not to download source packages after every clean
- fs/ - recipes for various output image options (tgz, squashfs and so on)
- system/skeleton/ - basic filesystem structure
The buildsystem is very fast and allows very high level of customizations.
Sat, 03 Jan 2015 17:58:13 +0000
When you see the following kind of errors during cross compilation (linking phase):
ld: warning: libfontconfig.so.1, needed by .../libQtGui.so, not found (try using -rpath or -rpath-link)
ld: warning: libaudio.so.2, needed by .../libQtGui.so, not found (try using -rpath or -rpath-link)
There could be two reasons:
- the list of required binaries is not complete and linker cannot complete the linking automatically
- your $SYSROOT/usr/lib is not passed to linker by -rpath-link as mentioned in error message
During normal native build your libraries are stored in standard locations (/usr/lib) and locating libraries is easier. Cross compilation needs more attention in this ares as SYSROOT is not standard.
Then search for LDFLAGS setup in your build scripts:
LDFLAGS="-L${STAGING_LIBDIR}"
And change to the following:
LDFLAGS="-Wl,-rpath-link,${STAGING_LIBDIR}-L${STAGING_LIBDIR}"
The clumsy syntax -Wl,<options-with-comma-as-space> tells your compiler (that is used for linking purposes) to pass the options (with commas replaced by spaces of course) to linker (ld).
Sat, 03 Jan 2015 18:13:47 +0000
Few, most important in my opinion, however mostly overlooked GCC compiler switches:
- -Wall: enables all the warnings about constructions that some users consider questionable, very likely a programming mistakes
- -Wextra: enables some extra warning flags that are not enabled by -Wall
- -Winit-self: warn about uninitialized variables which are initialized with themselves
- -Wold-style-cast: warn if an old-style (C-style) cast to a non-void type is used within a C++ program
- -Woverloaded-virtual: warn when a function declaration hides virtual functions from a base class
- -Wuninitialized: warn if an automatic variable is used without first being initialized
- -Wmissing-declarations: warn if a global function is defined without a previous declaration
- -ansi, -std=standard: specify the C/C++ standard level used
- -pedantic: issue all the warnings demanded by strict ISO C and ISO C++, and -pedantic-errors that tunrs them into errors (aborts compilation)
and the most important one:
- -Werror: turns warnings into errors, so your build would go red in case of any warning
I must admit we used to use "-Werror" extensively for many years and many pitfalls are omitted then automatically.
Fri, 22 Jan 2016 20:24:00 +0000
 Writing Makefiles is a complicated process. They are powerful tools and, as such, show quite high level of complexity. In order to make typical project development easier higher level tools have been raised. One of such tools is CMake. Think of CMake for Make as C/C++ compiler for assembly language. Writing Makefiles is a complicated process. They are powerful tools and, as such, show quite high level of complexity. In order to make typical project development easier higher level tools have been raised. One of such tools is CMake. Think of CMake for Make as C/C++ compiler for assembly language.
CMake transforms project description saved in CMakeLists.txt file into classical Makefile that could be run by make tool. You write your project description in a high level notation, allowing CMake to take care of the details.
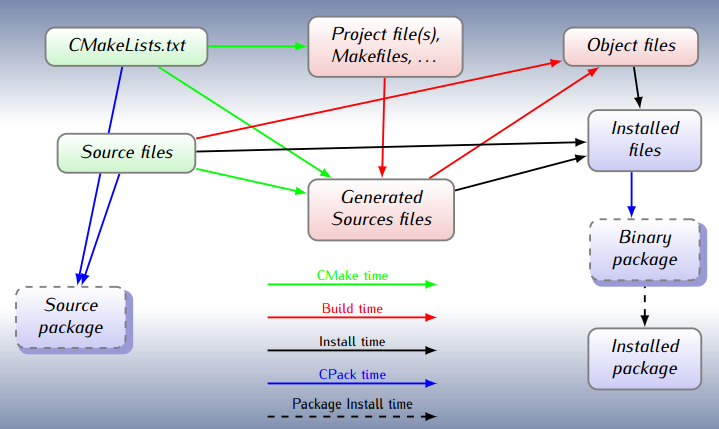
Let's setup sample single source code executable, the simplest possible way (I'll skip sample_cmake.cpp creation as it's just C++ source code with main()):
$ cat CMakeLists.txt
cmake_minimum_required(VERSION 2.8)
project (SampleCmake)
add_executable(SampleCmake sample_cmake.cpp)
Then the build:
$ cmake .
-- The C compiler identification is GNU
-- The CXX compiler identification is GNU
-- Check for working C compiler: /usr/bin/gcc
-- Check for working C compiler: /usr/bin/gcc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Configuring done
-- Generating done
-- Build files have been written to: /home/darek/src/cmake
$ make
Scanning dependencies of target SampleCmake
[100%] Building CXX object CMakeFiles/SampleCmake.dir/sample_cmake.cpp.o
Linking CXX executable SampleCmake
[100%] Built target SampleCmake
After the procedure one can find the output in current directory: SampleCmake binary (compiled for your host architecture, cross-compiling is a separate story).
More complicated example involves splitting project into separate shared library files. Let's create one in a subdirectory myLibrary/, new CMakeLists.txt there:
project (myLibrary)
add_library(MyLibrary SHARED sample_library.cpp)
Then you need to reference this library from Main CMakeLists.txt file:
add_subdirectory(myLibrary)
include_directories (myLibrary)
target_link_libraries (SampleCmake MyLibrary)
What happens there?
- myLibrary subdirectory is added to the build
- subdirectory for include files is specified
- SampleCmake binary will use MyLibrary
Let's build the stuff now:
$ cmake .
-- Configuring done
-- Generating done
-- Build files have been written to: /home/darek/src/cmake
$ make
Scanning dependencies of target MyLibrary
[ 50%] Building CXX object myLibrary/CMakeFiles/MyLibrary.dir/sample_library.cpp.o
Linking CXX shared library libMyLibrary.so
[ 50%] Built target MyLibrary
Scanning dependencies of target SampleCmake
[100%] Building CXX object CMakeFiles/SampleCmake.dir/sample_cmake.cpp.o
Linking CXX executable SampleCmake
[100%] Built target SampleCmake
Then you will get: an executable in current directory (SampleCmake) and a library in subdirectory (myLibrary/libMyLibrary.so).
Of course, some "obvious" make targets (as make clean) would work as expected. Others (make install_ might be enabled in a CMake configuration.
Interesting function (also visible in QMake) is the ability to detect changes in CMake project files and autoatically rebuild Makefiles. After 1st CMake run you don't need to run it again, just use standard make interface.
Sat, 16 Apr 2016 07:04:53 +0000
 Yocto is an Open Source project (based, in turn, on OpenEmbedded and bitbake) that allows you to create your own custom Linux distribution and build everything from sources (like Gentoo does). Yocto is an Open Source project (based, in turn, on OpenEmbedded and bitbake) that allows you to create your own custom Linux distribution and build everything from sources (like Gentoo does).
It's mostly used for embedded software development and has support from many hardware vendors. Having source build in place allows you to customize almost everything.
In recent years I was faced with problem of development integration - to allow distributed development teams to cooperate and to supply their updates effectively for central build system(s). The purpose of this process:
- to know if the build is successful after each delivery
- to have high resolution of builds (to allow regression tests)
- and (of course) to launch automated tests after each build
So we need some channel that would allow to effectively detect new software versions and trigger a build based on them. There are two general approaches for this problem:
- enable a "drop space" for files with source code and detect the newest one and use it for the build
- connect directly to development version control systems and detect changes there
1st method is easier to implement (no need to open any repository for access from vendor side). 2nd method, however, is more powerful as allows you to do "topic builds", based on "topic branches", so I'll focus on second approach there.
bitbake supports so called AUTOREV mechanism for that purpose.
SRCREV = "${AUTOREV}"
PV = "${SRCPV}"
If it's specified such way latest source revision in the repository is used. Revision number (or SHA) is used as a package version, so it's changed automatically each time new commit is present on given branch - that's the purpose we place ${SRCREV} inside PV (package version) veriable.
Having such construction in your source repository-based recipes allows you to compose builds from appropriate heads of selected branches.
Of course, on each release preparation, you need to fork each input repository and point to proper branches in your distro config file. Then the process should be safe from unexpected version changes and you can track any anomaly to single repository change (ask vendor to revert/fix it quickly if needed or stick to older version to avoid regression for a while).

|
Tags
|







